
Case Study
1. Introduction and Use Case
Beekeeper is an open-sourced Backend as a Service (BaaS) built to handle bursty traffic from one-off events like a sale or promotion.
There is a difference between infrastructure needed for normal business activities and infrastructure needed for high traffic one-off events. An abrupt increase in website traffic can be the effect of many different causes. One such cause is an event like a Black Friday sale or similar promotion. If the existing infrastructure is unprepared for the spike in traffic it may result in a inadvertent Denial of Service. The desired service may be unavailable until traffic declines to a manageable level.
1.1 Hypothetical
Let's look at a hypothetical. The Seal Brewing Company is planning a promotion to sell some seasonal, limited-run beers. Their promotion involves something more than a simple read of static content; there is something dynamic about it for each user, perhaps a requirement to log in or sign up before making a purchase. Seal Brewing knows when the event will occur and they're planning to spread the word via typical marketing channels like email, Facebook, Twitter, etc. The URL where this promotion will live is not known by the general public yet and they will not know until they get that email or see that post on Twitter. But when they do find out the URL a big burst of traffic may overwhelm the existing infrastructure and now this promotion has taken down the site by causing cascading failures in other components and disrupted normal business activities across Seal Brewing as a whole.

2. Potential Solutions
2.1 Scaling or Rebuilding Existing Infrastructure
Seal Brewing could explore increasing the capacity of its existing architecture. Now they can handle the bursty traffic for the promotion but the trade-offs could be substantial. First, they might have legacy infrastructure that can't be scaled. Perhaps certain components cannot scale vertically and perhaps others cannot be easily replicated or partitioned and scaled out.
Let's assume Seal Brewing can scale up its infrastructure somehow. Now they're capable of handling large traffic loads every day of the year but this is probably not the best return on investment. Seal Brewing is either buying more expensive hardware than they usually need (scaling vertically) or they're buying economical hardware but in larger quantities (scaling horizontally). The extra capacity is remaining unused most of the year.
What if they rebuild their functionality in a different way, perhaps on entirely new components with a cloud provider that can scale up and down with ease? Seal Brewing may be unwilling to spend the time and engineering resources required to rewrite its application.
Either way, Seal Brewing might be starting to think about a solution that can be tacked onto the legacy infrastructure. This is where a virtual waiting room fits in.
2.2 A Virtual Waiting Room
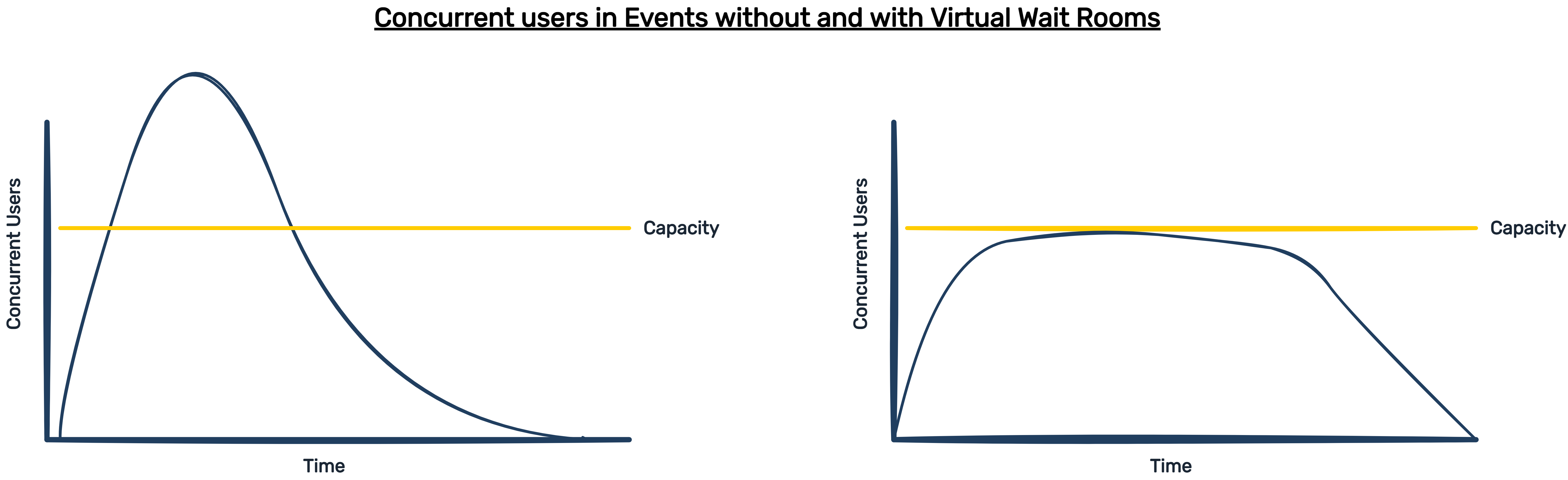
Beekeeper is an open-sourced Backend as a Service (BaaS) "virtual waiting room." In concept, a virtual waiting room is simply a public URL endpoint where users can be queued while they await their turn to go to the final destination URL where the actual promotion lives.
A virtual waiting room reduces the traffic sent to an endpoint below a set capacity over a period of time. The role of a waiting room is to “flatten the curve.”
2.3 How To Get a Virtual Waiting Room
A virtual waiting room seems like it fits the use case nicely, but how can Seal Brewing get one?
2.3.1 Buy a Third-Party Solution
As with any good problem, there is usually someone willing to sell a solution and virtual waiting rooms are no different. Queue-it, CrowdHandler, and Queue-Fair are all examples of third-party solutions for purchase.
The main trade-off of purchasing a paid solution is giving up some amount of control. Seal Brewing would not own the infrastructure and would be reliant on the third-party's implementation. Of course, purchasing a solution means they would be spending money as well, but this is not a material negative because building it yourself or even using an open-sourced solution may involve paying for more engineering hours.
2.3.2 Roll Your Own Waiting Room
This could be done with a cloud provider like Amazon's AWS. They have bespoke cloud services each with different specializations that can be created and linked up together. AWS even has information detailing one type of virtual waiting room and how one might go about using their services to create it.1
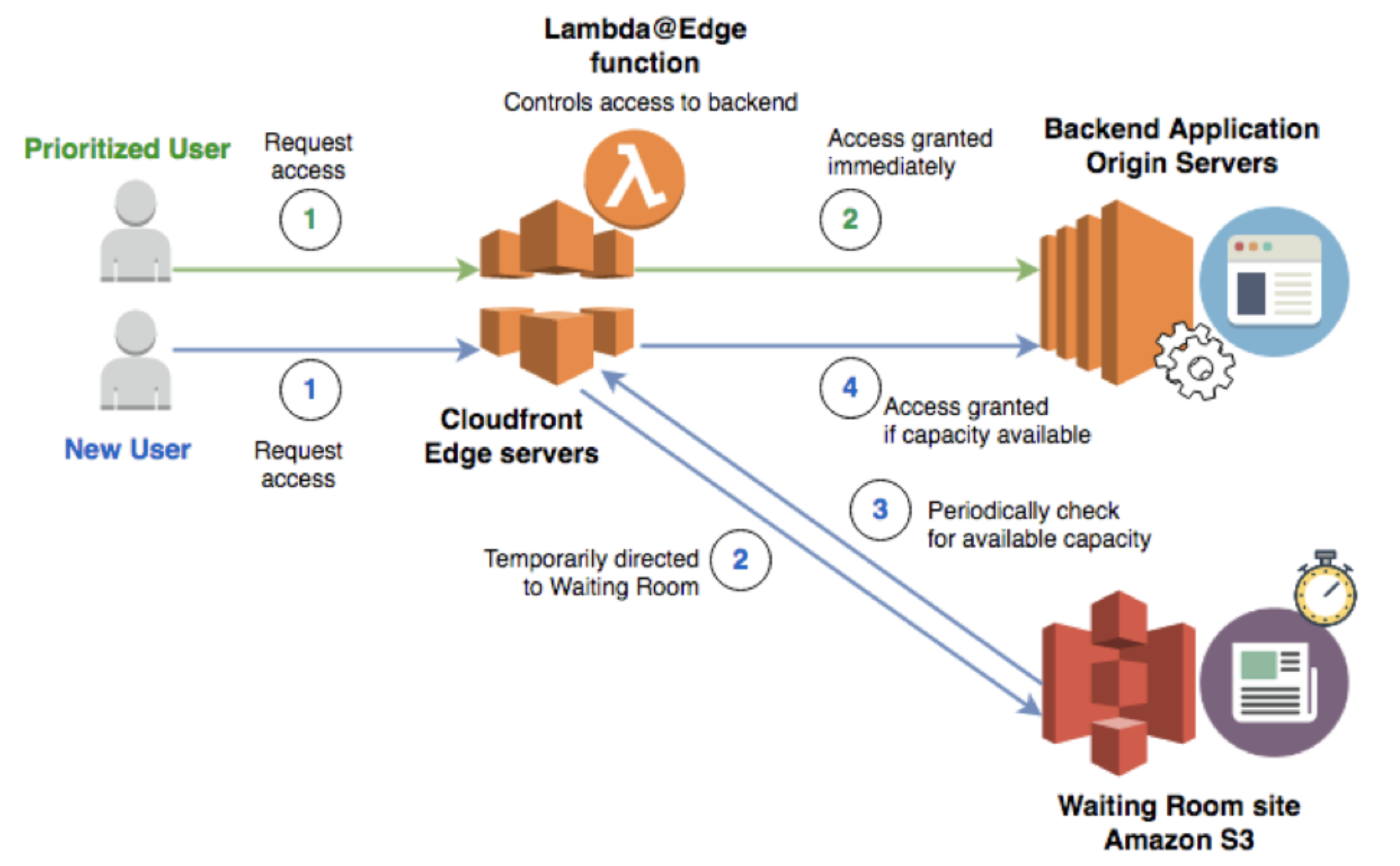
Building your own virtual waiting room involves several considerations. First, it means thinking about the tradeoffs involved with a virtual waiting room. What features should it have? How have the challenges associated with said features been overcome by other products on the market like Queue-it? Second, if you're going to use a cloud provider like AWS, it means getting acquainted with AWS. Unfortunately, this is no small thing. Learning what AWS services exist and what they can accomplish takes time. Finally, those two pieces of thinking must be married together: now that you know what features the waiting room ought to have, and now that you know what's possible with AWS services, you need to design the infrastructure you want and deploy it.
If that still seems like a lot of work it's because it is. An open-sourced solution is not free either in terms of time commitment, but if done well it is cheaper.
3. Introducing Beekeeper
3.1 BaaS
As mentioned, Beekeeper is an open-sourced BaaS built for organizations that have one-off promotions involving a dynamic event, are constrained by existing infrastructure or time and effort, and prefer to own their solution rather than purchase off the shelf from a third-party. Let's look at where BaaS sits on a spectrum of possibilities:
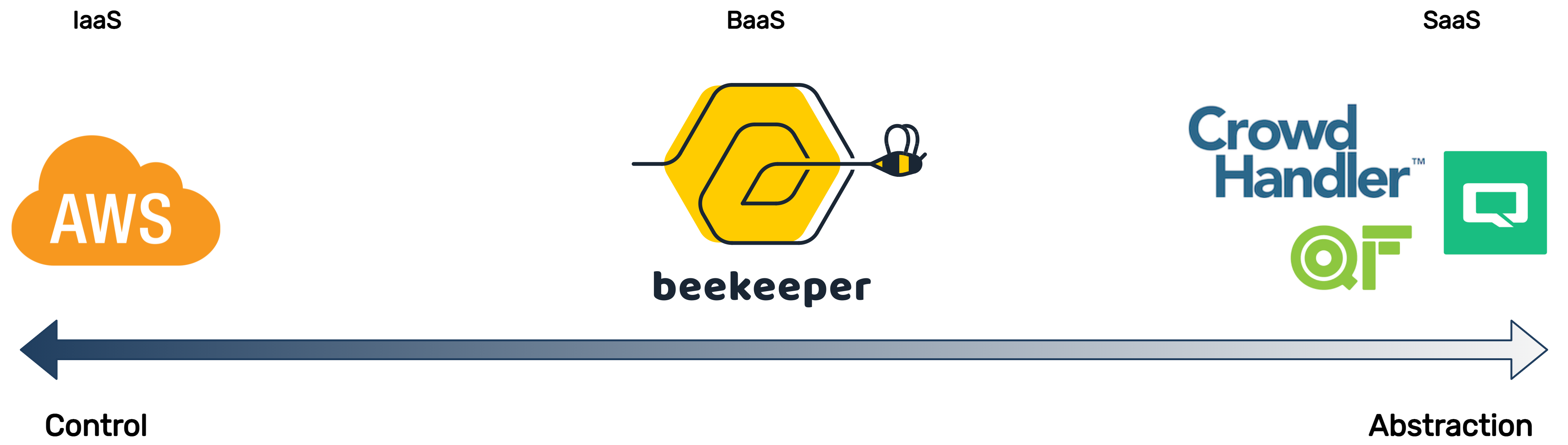
Developers deploying an application to bare metal servers must account for every part of the software stack, all the way down to hardware selection. Infrastructure as a Service (IaaS) abstracts away hardware concerns, leaving developers responsible for setting up the entire runtime environment including the operating system.
With even more abstraction, but typically less control, is something like Backend as a Service, which abstracts away server-side implementation entirely and simply provides an API to interact with the service. An example of a classic BaaS would be Heroku. At this end, most choices are made by the providers of the service; developers have little, if any, control over implementation details.
Beekeeper is BaaS because out of the box all the decisions are made and Seal Brewing only has to interact with the CLI tool. It is worth noting that the Beekeeper infrastructure is spun up on Seal Brewing's AWS account and they, therefore, have complete control to make changes to the implementation.
Before we go further into the solution it's probably worthwhile to refresh our memory of the problem and make clear a few more things.
3.2 Revisiting the Problem
Seal Brewing is going to hold a one-off event at a pre-determined time and URL that they will make the general public aware of via channels like email or social media. When the public finds out about the event they might flood the URL all at once. Somehow Beekeeper has to intercept this traffic. The one-off nature of the use case is what allows this to happen. The use case does not involve intercepting all of Seal Brewing's traffic. The waiting room URL can be put in these marketing emails and on these social media posts.
It is worth noting that a virtual waiting room is not needed for all types of bursty traffic problems. Simple reads and writes can be handled by placing content on a CDN and writing to a separate database that can handle the traffic.
A virtual waiting room solution only comes into play when the users must be allowed to continue to the final destination because the action they need to take is dynamic. Perhaps this means completing a purchase, itself which means having to log in with some credentials, both of which involve talking to existing legacy infrastructure that we are trying to avoid modifying or rebuilding.
3.3 The Beekeeper Solution
Beekeeper is an NPM package used to automate an infrastructure built on top of AWS services. We'll get into the basics of how you use the NPM package soon but for now, let's see what Seal Brewing gets with Beekeeper.
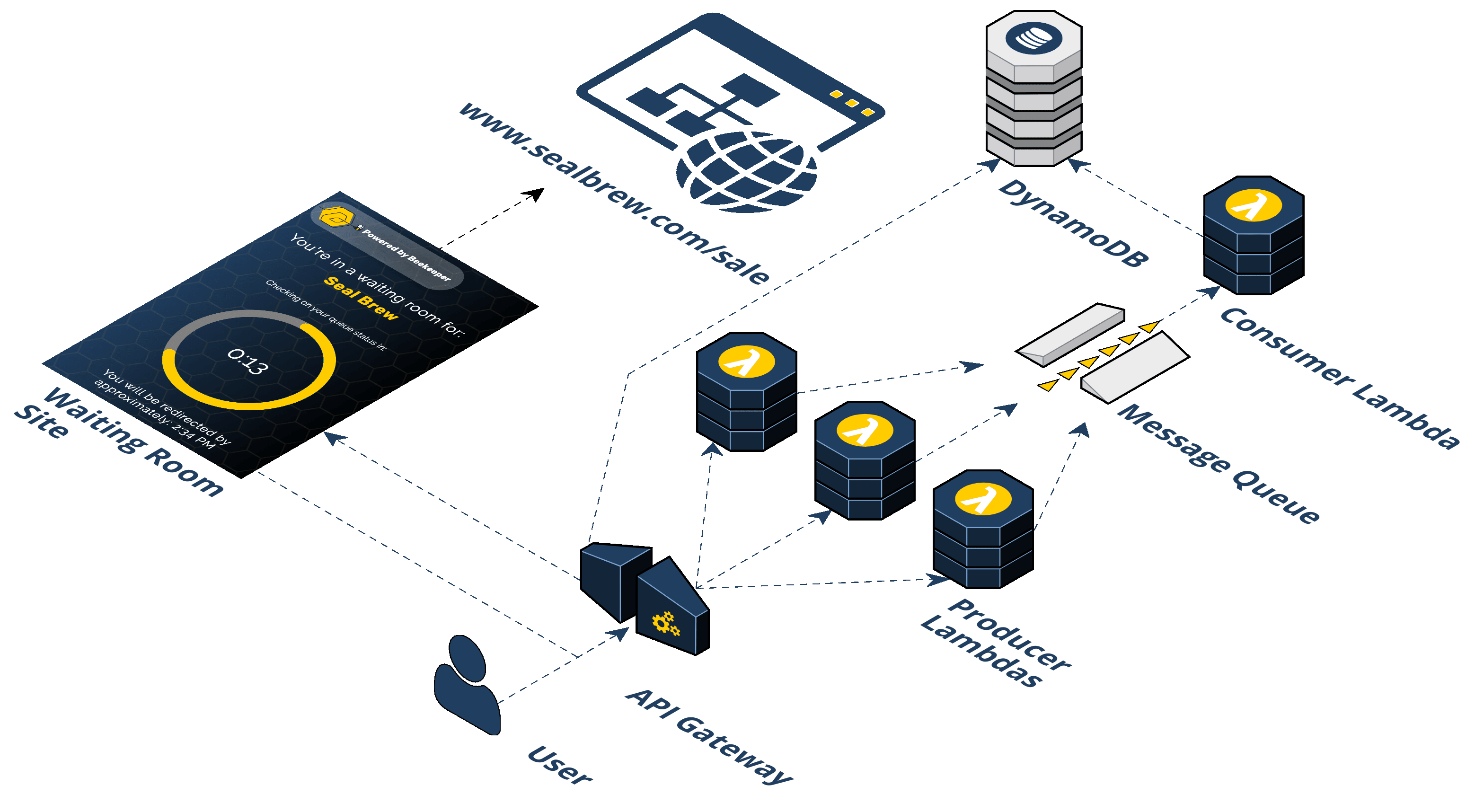
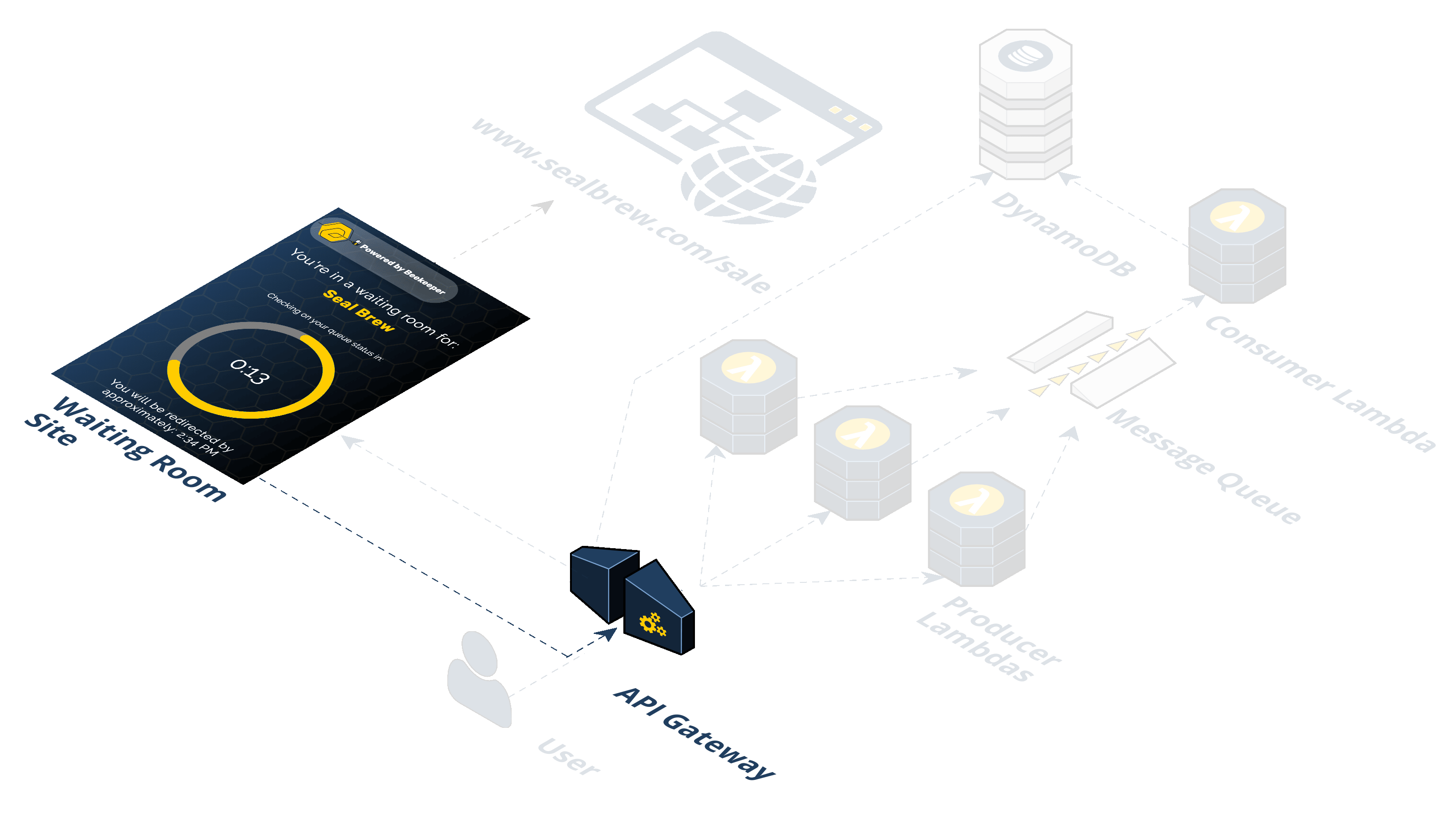
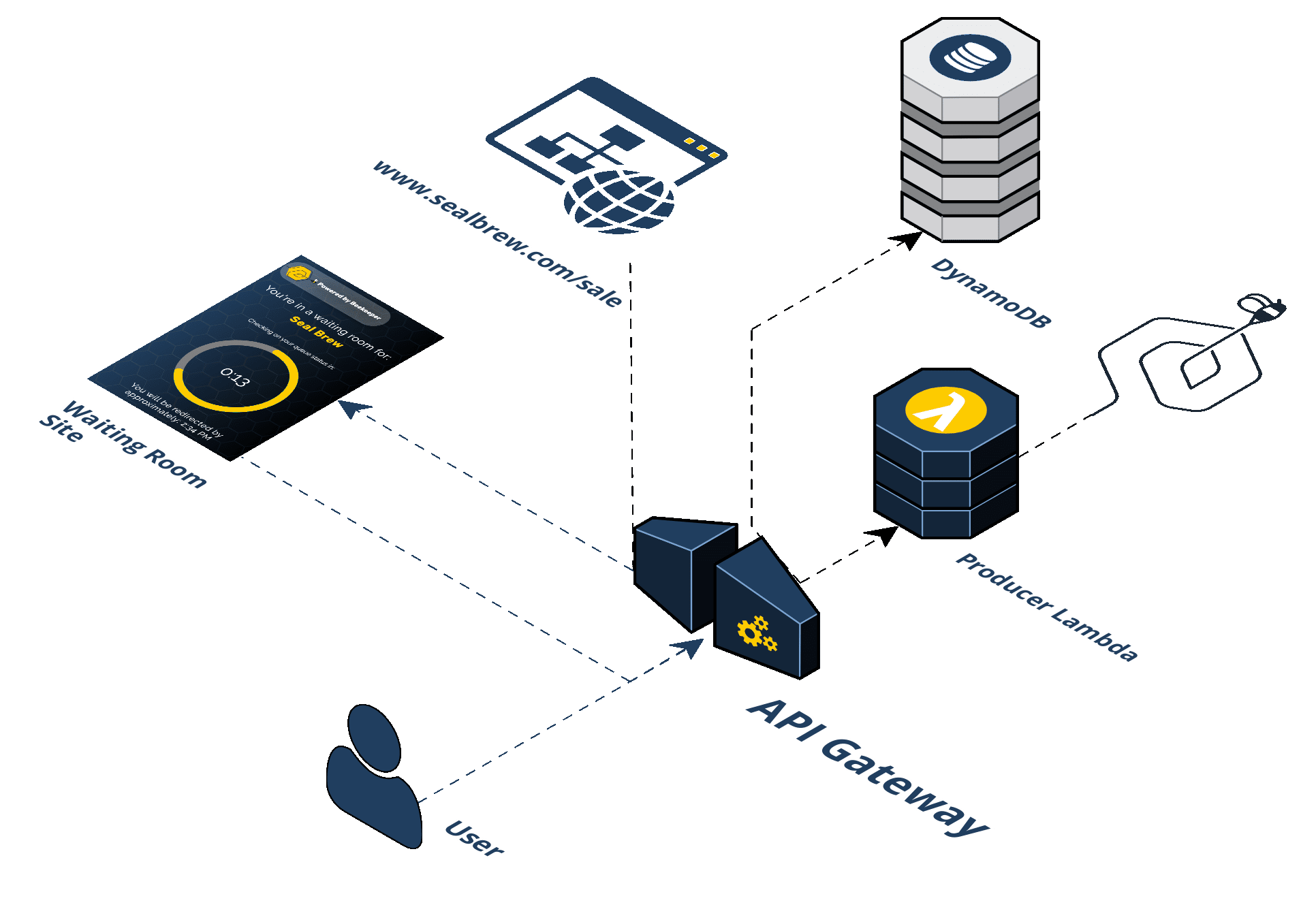
Beekeeper consists of five (5) distinct AWS services: API Gateway, S3, Lambda, SQS, and DynamoDB. The following steps describe the flow of the infrastructure:
Step 1: A user visits a promotion URL. Seal Brewing is going to run its promotional sale. They'll install and deploy the Beekeeper NPM package, provide a couple of pieces of information such as the final destination URL that the waiting room should forward to and at what rate. After deploying Beekeeper, Seal Brewing will get a generated URL to use for their promotion.
Step 2: Visiting the promotion URL hits the API Gateway. When the user clicks the URL, their browser is sending a GET request for a resource. That HTTP request to an endpoint is handled by the API Gateway and that endpoint triggers a Lambda. We call this the "/beekeeper" endpoint.
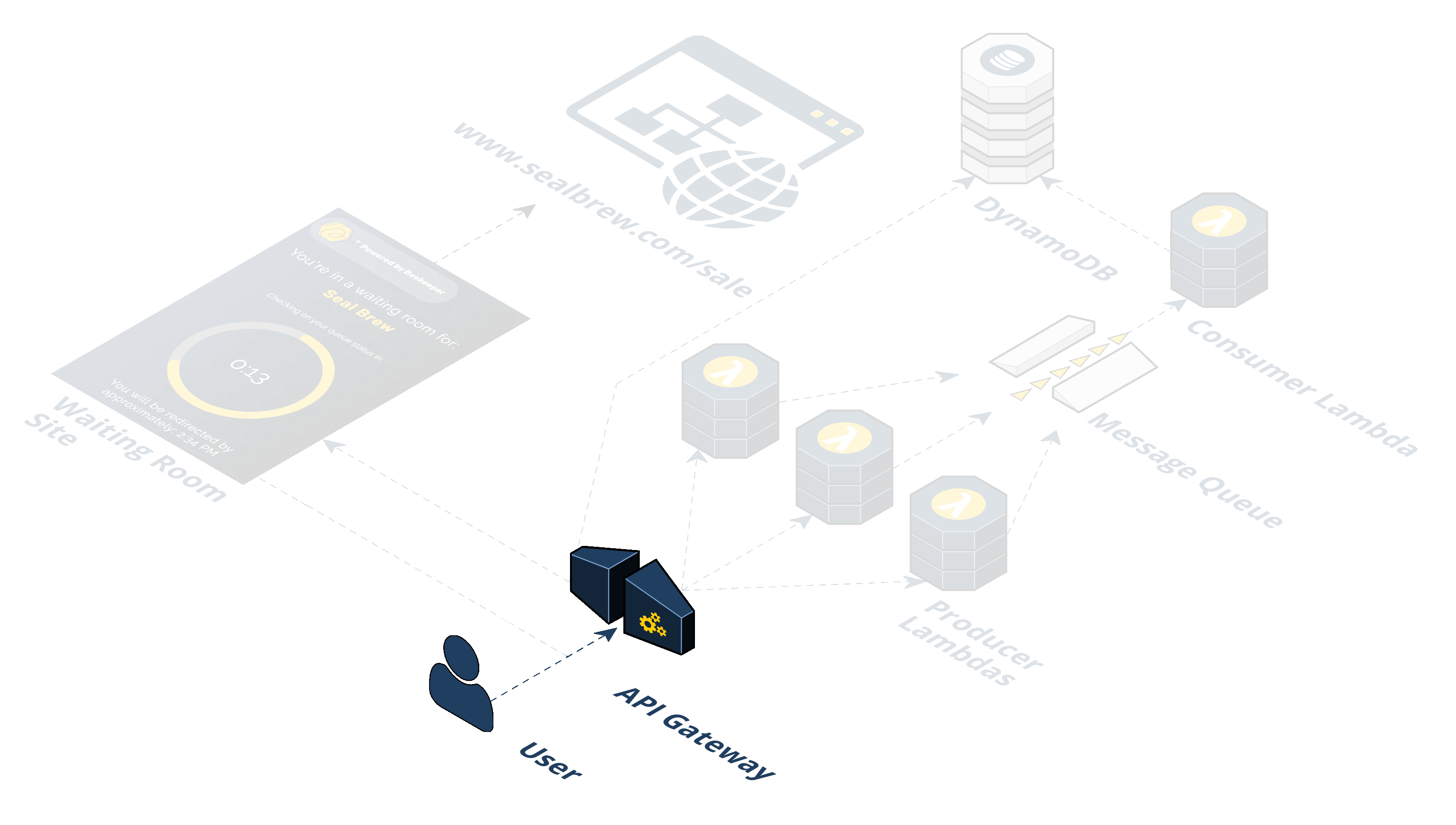
Step 3: The Producer Lambda is triggered. A Lambda is a container that AWS spins up with your specified runtime environment, dependencies, and code in it. It is a serverless compute service that runs code without having to provision resources or manage servers. The logic in the Producer Lambda does a few things. It first checks if the incoming request headers already have our cookie. If the incoming request does not have a cookie, a few additional steps take place. First, the Lambda generates a random token value. Second, the token is placed in a queue (SQS). Third, a cookie is set on the client with this token in it. Fourth, a response header is set that tells the browser when it receives the HTTP response from the API Gateway to redirect the client to the waiting room URL. This waiting room URL consists of static assets; an HTML file with JavaScript and CSS held in an AWS S3 bucket. We'll come back to this waiting room in the S3 bucket, but for now, let's continue by talking about what happens after the token gets put in the queue.
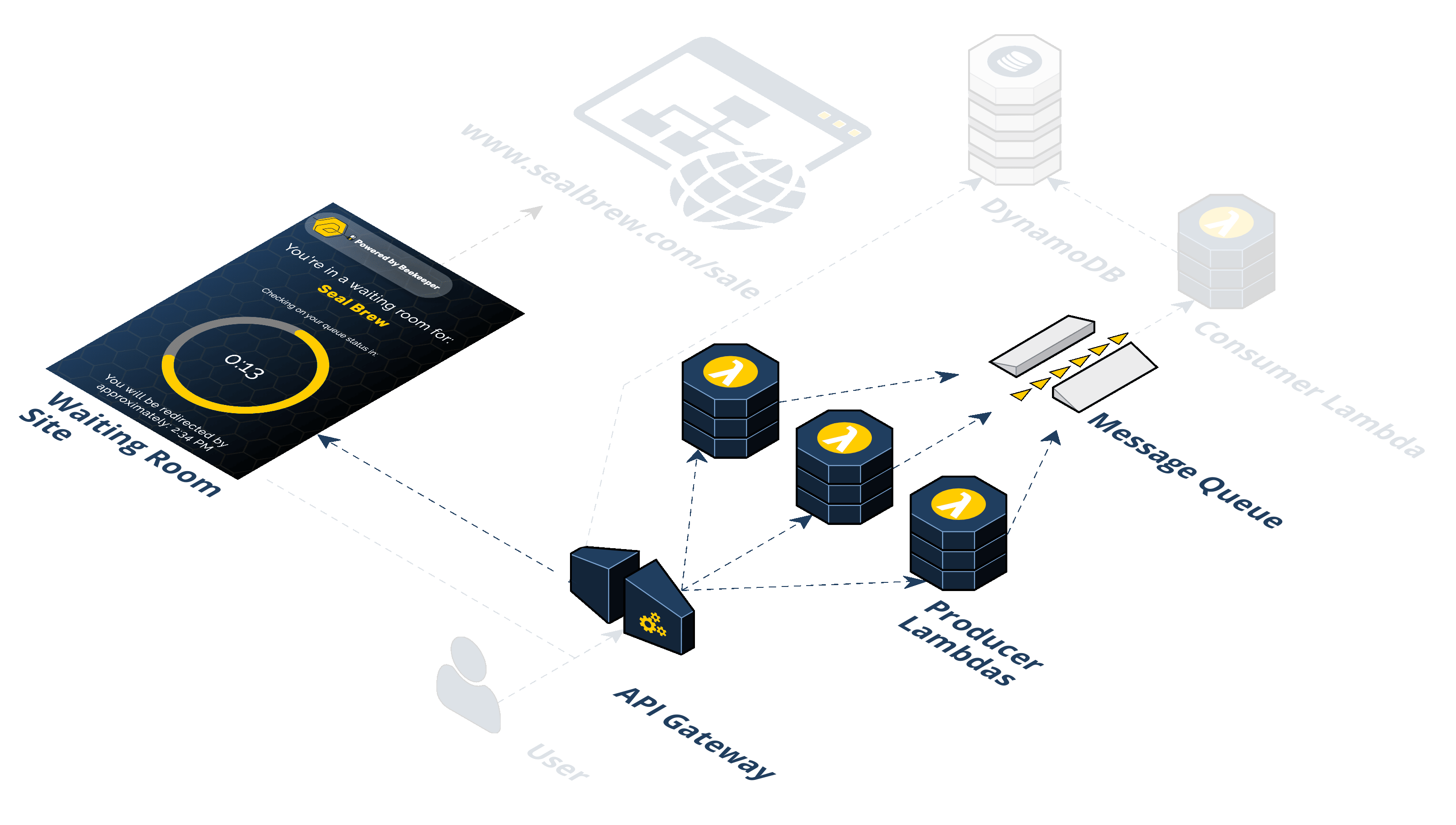
Step 4: The Consumer Lambda pulls from the SQS queue. A grouping of Consumer Lambdas work to pull these tokens off the queue at a specific rate. The Consumer Lambdas take tokens off the queue and write them to the DynamoDB. This is how Beekeeper controls the rate of traffic flow.
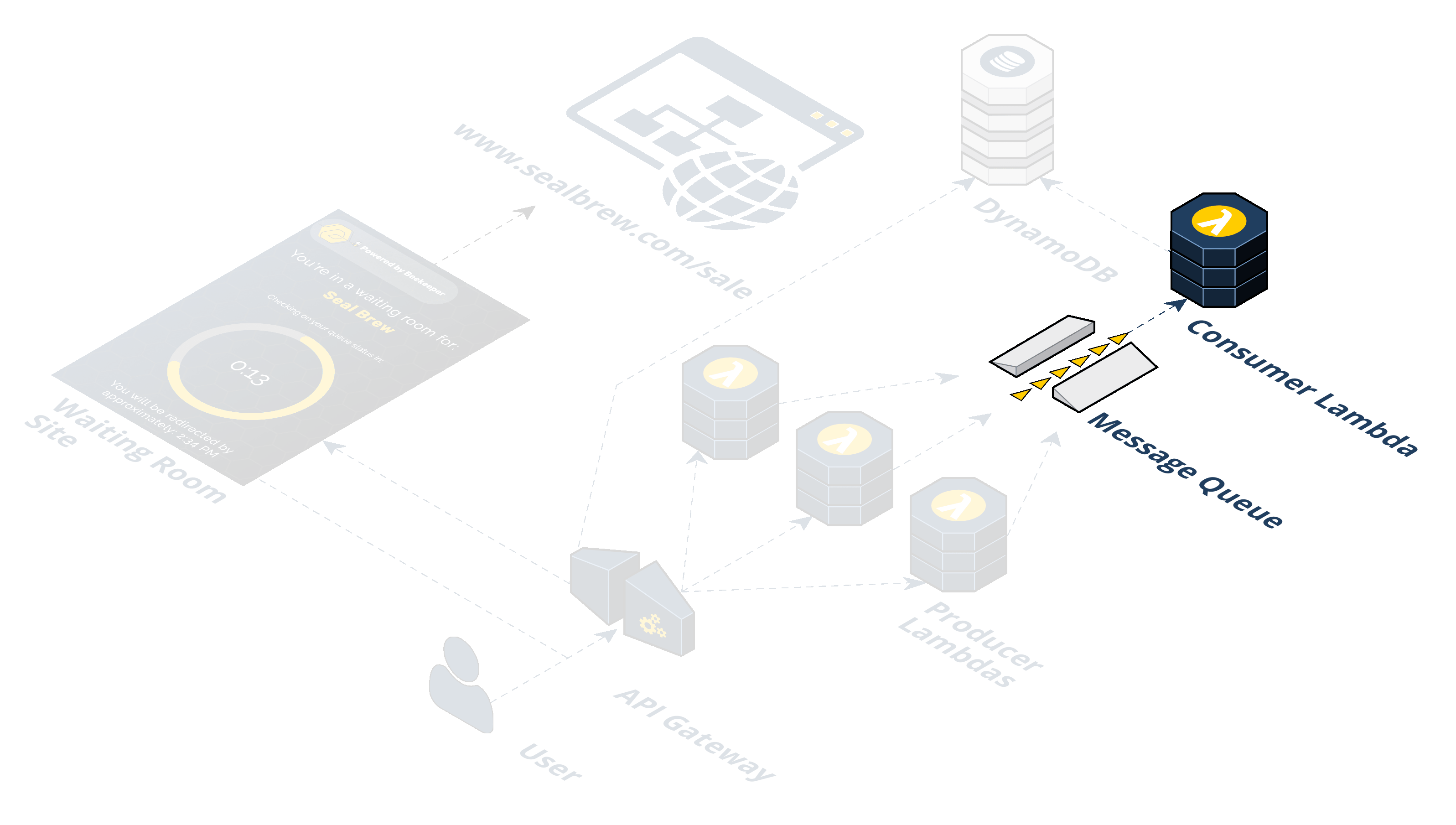
Step 5: The token is written to the DynamoDB. Now that the Consumer Lambda has pulled off a given token it writes an object to the DynamoDB containing the token, the current date, and a property indicating with a boolean value whether this token is allowed to redirect to the waiting room.
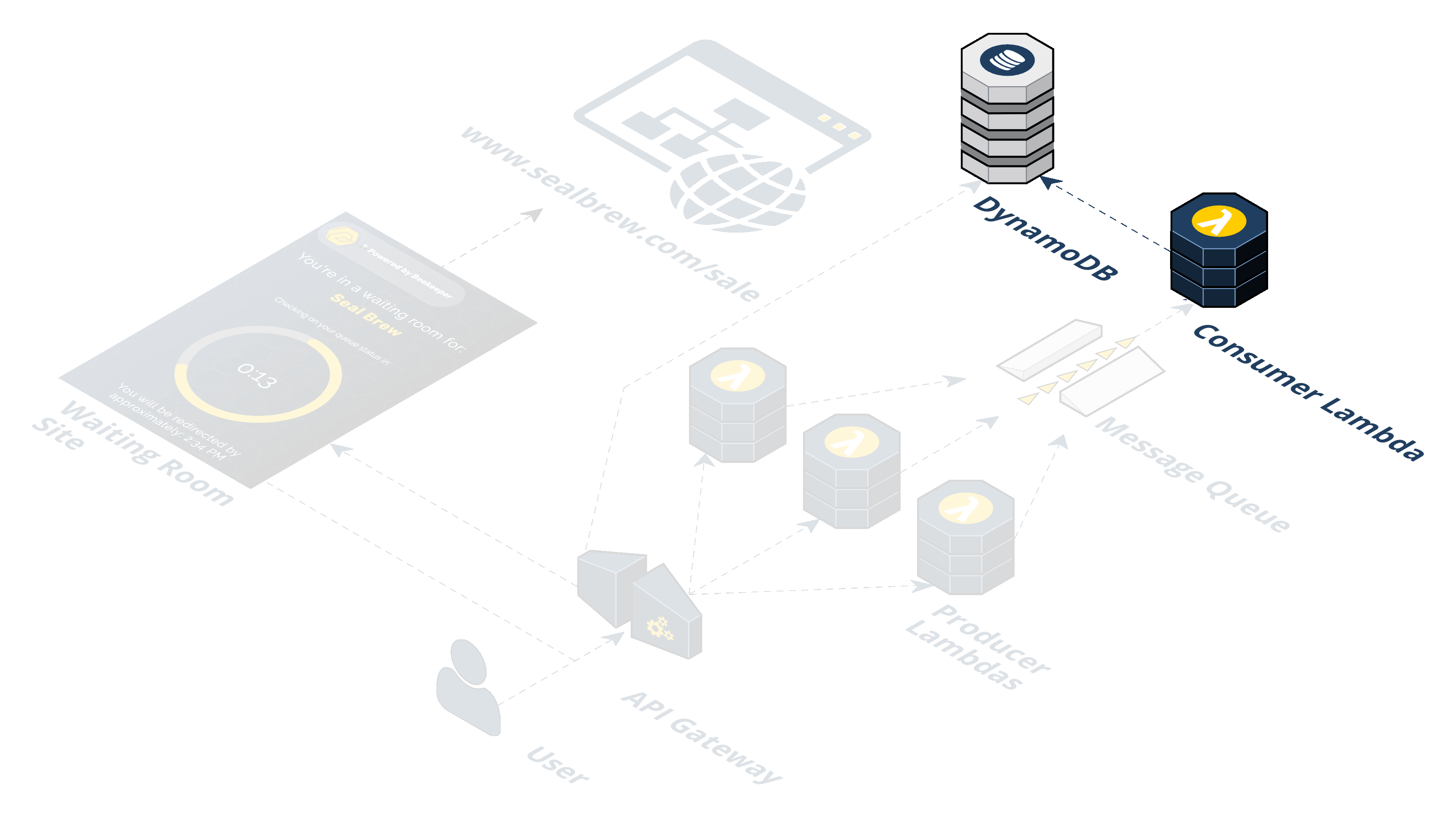
Step 6: The waiting room in the S3 bucket polls the API Gateway. The waiting room has client-side JavaScript sending AJAX requests to an endpoint on the API Gateway every 20 seconds. We call this the "/polling" endpoint. Instead of triggering a Lambda, the API Gateway pulls off the cookie from the incoming request to get the token and directly queries the DynamoDB to check if the token is in there.
Step 7: Query DynamoDB to see if the token is in there yet. This is how we decide when to let a user get redirected from the waiting room to the final destination.
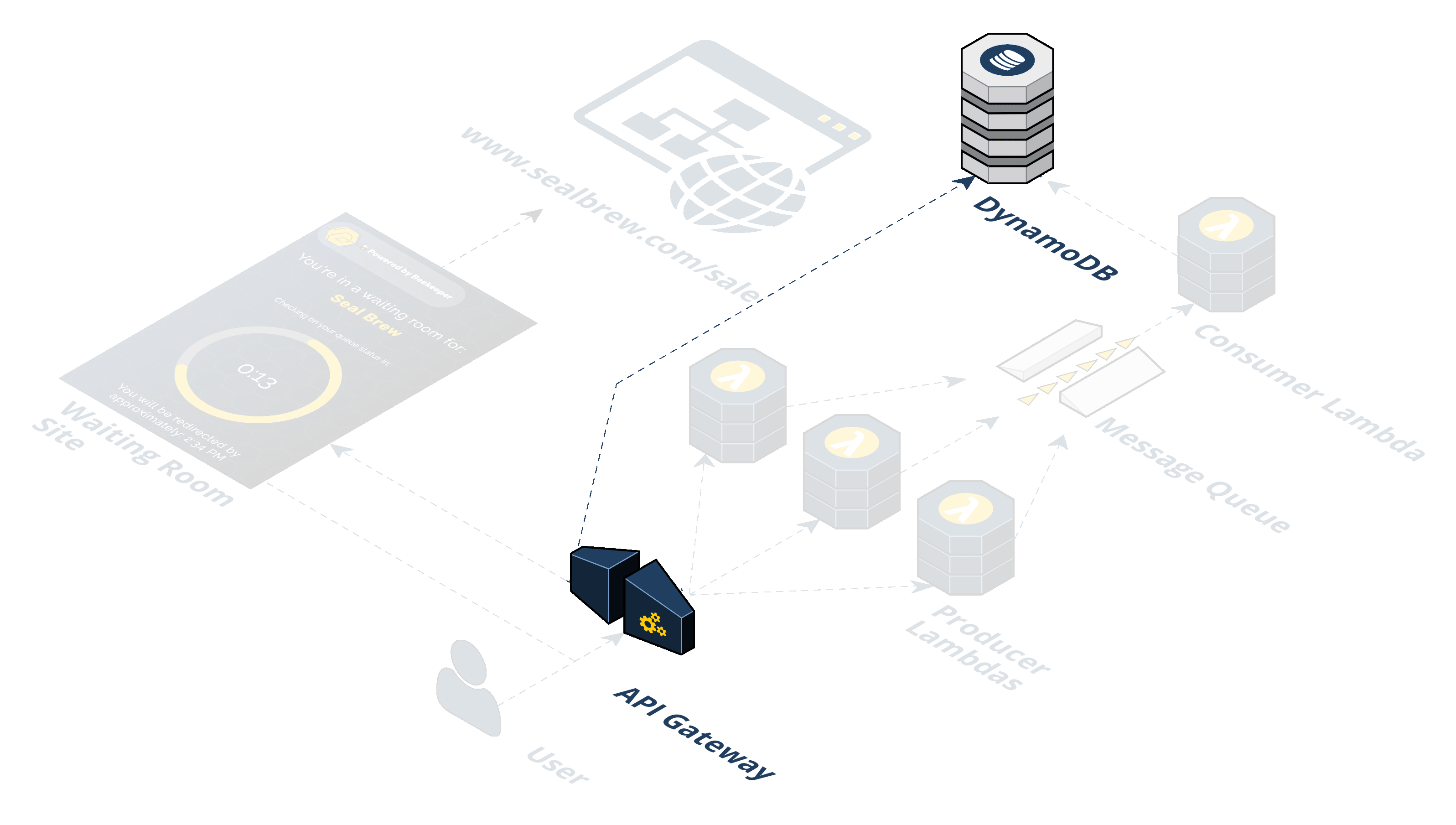
If the token is in the database, the API Gateway responds with an object with two properties:
{
"allow": "true",
"origin": "https://www.sealbrewing.com"
}
The browser checks the "allow" property and if it is truthy the browser redirects the user to the URL provided in the "origin" property. If the token is not in the database, the API Gateway responds with an object with one property:
{
"allow": "false"
}
and the polling continues every 20 seconds while the user waits.
Step 8 (Optional): The final destination performs a check to make sure the user didn't skip the waiting room. Without this step, notice how a user could technically skip the waiting room. Here's how it might happen: one user clicks on the promotional link, goes through the whole process outlined above, and makes it to the final destination. Now they know the URL of the final endpoint where the promotion is. They could share that URL on Twitter or Reddit, for example, and now others could go there directly. Note that Seal Brewing probably does not have to be overly concerned with this potential problem. The sharer would have to be influential and the event long-lived such that other users could actually find out about that shared URL. In any case, to prevent users from circumventing the waiting room we have a third endpoint on the API Gateway that we call the "/client" endpoint. If Seal Brewing wants, they can add a simple AJAX request to their frontend JavaScript that will send a GET request to the "/client" endpoint. The browser would send along the cookie with such a request. The logic works the same as in the "/polling" route in Step 7; A direct query of the database occurs and Seal Brewing can expect a JSON object in response with a property "allow" that contains a truthy or falsey value.
4. How To Use Beekeeper
To set up a Beekeeper waiting room, Seal Brewing must have an AWS account, set their access keys, download the AWS CLI, and have Node and NPM installed on their machine. Once those preliminary steps are finished, deploying a virtual waiting room takes just a few minutes to set up and is torn down in seconds.
It is possible to set up multiple virtual waiting rooms. For each one, Seal Brewing will be asked six questions such as the name they want publicly displayed on the waiting room page, the AWS region where the infrastructure is deployed, the endpoint of the event, and the rate at which traffic should be sent from the waiting room to that endpoint.
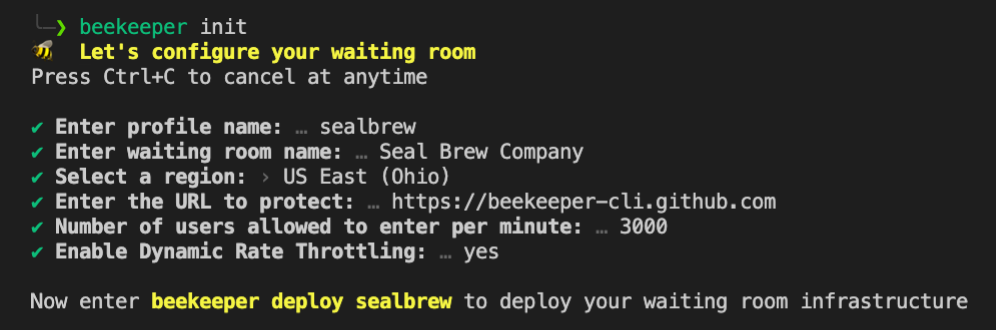
Deploying the waiting room builds up all the required components and permissions. Once the build is done two URLs are generated; the waiting room URL is put in the promotional emails and social media posts and the client check endpoint can optionally be utilized by Seal Brewing to prevent people from skipping the queue.
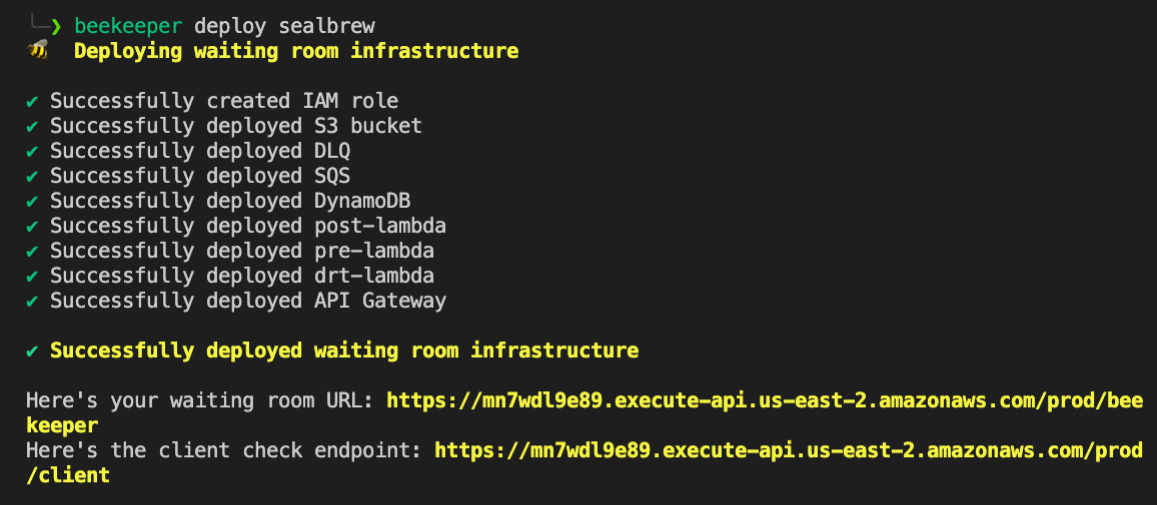
If the waiting room is no longer needed but the advertising links are still being used the waiting room can be turned off and visitors will redirect to Seal Brewing's endpoint directly, skipping the waiting room.

When finished with the waiting room entirely is can be torn down in seconds with a simple command. Detailed instructions for using Beekeeper can be found in our README.
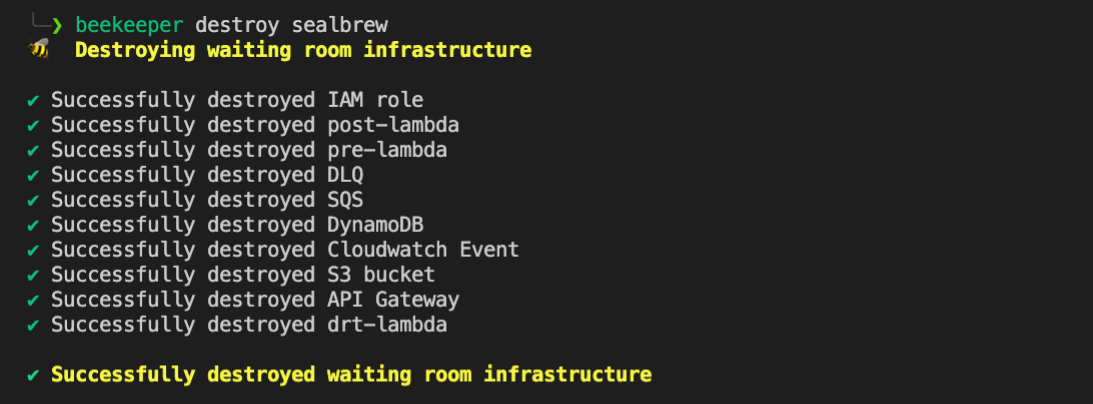
5. Engineering Decisions and Trade-Offs
The Beekeeper team encountered a few engineering challenges and made several important decisions when designing and building the infrastructure.
5.1 Edge Optimization Versus Regional Deployment
One of the first forks in the road was whether to put the waiting room on the edge or not. Putting assets or functions on the edge means bringing them closer to end-users to reduce latency.
For example, with AWS CloudFront, you can put a static asset in an S3 bucket and create a CloudFront distribution for it. Now the asset no longer resides on a server in a single geographic location like "us-east-1.," which is in Virginia. Instead, identical versions of the asset live in many locations across the globe. When a user makes an HTTP request for it, the asset is served from the lowest latency location, typically the location closest to the request. Without edge optimization, a request from Los Angeles might take 70ms to get to a server in Amazon's "us-east-1" region and set up a TCP handshake, and another 70ms for the actual round trip of data back in response. If the asset is distributed to a location very close to the user it might take 10ms or less. For example, a round trip ping from Los Angeles to San Diego could be as fast as 4ms for the TCP handshake and another request/response cycle for the actual data.2
In addition to serving static assets on the edge, many cloud providers, including Amazon, provide the ability to do computation on the edge above and beyond serving static assets like an HTML page. Specifically, a function can be distributed and executed in various geographic locations through Amazon's Lambda@edge service.
Should the Beekeeper virtual waiting room be edge optimized? The initial temptation is certainly to edge optimize it. Let's assume the waiting room loads in under 50ms for everyone with edge optimization as compared to say 500-1000ms for a far-flung end-user trying to hit a centrally located server. Has anything of significance been achieved with edge optimization in that scenario? Reducing latency with edge optimization is great for a lot of use cases, but it doesn't seem to be useful here. The goal of a virtual waiting room is to intercept and diffuse a burst of traffic. Client-side JS polls every 20 seconds and when the user's token is written to the database they can proceed to the final destination. This user might be waiting for many seconds or many minutes. There is no discernible benefit for a site visitor that can get the waiting room loaded in 50ms versus 500ms.
If a user was interacting with a web application and every time they clicked a new page they experienced a second of latency, that would be a bad user experience. That is not the use case of a virtual waiting room; it's a single click to load a single page. If they're going to wait minutes anyway, what's the point of loading the waiting room in under 50ms? Edge optimizing like this can be characterized as "hurry up and wait." In other words, optimizations are made to "hurry" the site visitor to the waiting room, and then they simply wait with no benefit.
For the vast majority of situations, even global promotions with a user in Hong Kong and an infrastructure in the United States, users will have the waiting room page loaded in an acceptable amount of time that does not give a "broken" feeling. Further, most events/promotions will have a more regional use case, typically within the same country.
The extra complexity of making the waiting room and all its services edge optimized did not provide a commensurate benefit for Beekeeper given that it is a "waiting room." All Beekeeper's AWS services are located in a single region to be specified by Seal Brewing when deploying our NPM package; they can choose from one of 25 different AWS locations to deploy the infrastructure.
Let's now turn to one of the AWS services Beekeeper chose to use, API Gateway.
5.2 Choosing API Gateway
When we first started designing Beekeeper we began with an infrastructure based on a waiting room in an S3 bucket on a CloudFront distribution. However, we still needed some logic in a Lambda and the only way to trigger a Lambda with that approach was using one of the CloudFront triggers AWS offers. That approach lacked flexibility because triggering a Lambda with a CloudFront trigger in our original design only allows logic to take place in the Lambda code. This means a Lambda must be used for every kind of request. Instead, we chose to use a different service offered by AWS called API Gateway. API Gateway is more flexible and powerful.
What makes API Gateway powerful is it provides an opportunity to perform checks and modify data at different stages of the HTTP request/response cycle. API Gateway's flexibility allows it to proxy directly with other services, obviating the need for additional lambdas. Our API Gateway leverages this power and flexibility to create a central hub that exposes three distinct routes for interacting with the beekeeeper infrastructure.
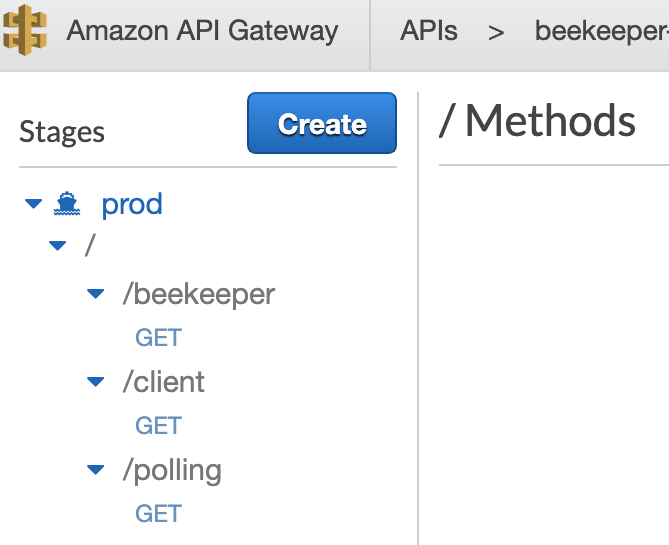
5.2.1 /beekeeper
Lambdas have an option to be triggered as a proxy integration. Choosing a proxy integration means that API Gateway will forward the unmodified request in its entirety to the Lambda code. Not choosing proxy integration means that the API Gateway can make modifications to the request, such as creating and transforming data, and then sending that modified data to the Lambda. We use proxy integration and trigger a Lambda (Producer Lambda) for new users hitting the initial endpoint. The Producer Lambda checks the incoming request's headers for the existence of the cookie and if it's not present, the Producer Lambda generates a token and creates a response header setting a cookie with that token in it. The Producer Lambda then sets other headers relating to Content-Type, Location, and various Access-Control-Allow headers. The Producer Lambda also sets the response status code to 302 indicating a redirect. Once this custom object is formed, the Producer Lambda responds to API Gateway with it via the proxy integration and API Gateway in turn responds to the client causing a redirect to the waiting room URL which is an endpoint representing the static asset in S3.
5.2.2 /polling and /client
Our /polling and /client routes serve as direct proxies to our DynamoDB. The database is queried from either the waiting room site (S3 Bucket) or the client endpoint. The logic is simple enough that we don’t need to use a lambda.
5.2.3 Directly Querying DynamoDB and VTL
A request comes in from the client-side JS and API Gateway directly queries DynamoDB to check for the token. This time we did not use proxy integration and instead took advantage of API Gateway’s ability to access and transform the request/response cycle. This is done using AWS Mapping Templates, which in turn use Apache Velocity Template Language (VTL).
Mapping Templates and the VTL syntax allow us to get access to information about the request, like parameters or headers. We're dealing with an HTTP request and DynamoDB does not speak HTTP; it expects to be communicated with in a specific syntax. With VTL we can access a cookie off the headers of the HTTP request and then format a JSON object with this data in a syntax DynamoDB expects to receive. In other words, we can get the information we need to make a proper query to the database directly from API Gateway.
DynamoDB's response will also not be a suitable HTTP response to send back to the client either. The Integration Response phase of API Gateway from the diagram above allows us to intercept the database response and perform manipulation with VTL. We can create a JSON object that API Gateway can send back as the response body. For the "/polling" resource, just two properties are in this object, one telling the client-side JS whether the token has an associated "allow" property of true, and the final destination to redirect the user to. For the "/client" resource, just one property is in this object, "allow" which is a boolean, either true or false.
In summary, API Gateway is powerful and has built in flexibility to add Request/Response logic with VTL. This means logic doesn't always have to live in a Lambda, which in turn means we don't always have to use a Lambda.
5.3 DynamoDB and Lack of Database Caching
Beekeeper is storing records that have three simple properties per collection stored in a single table of DynamoDB:
{
date: Date.now(),
usertoken: message.Body,
allow: true,
}
This data is all we need to store for each site visitor. When choosing a database the goal is usually to easily store data and easily access it. If the data is relational in nature, for example, there are "users" and "products" and "orders" and these types of objects relate to each other, then a SQL database might be the right choice. In Beekeeper's case, we do not have multiple types of data that interrelate. Our data is unrelated and stored in separate collections in a single table. Therefore, a NoSQL database in DynamoDB made the most sense. Scaling is another consideration and horizontal scaling is notoriously difficult with SQL databases. We'll explain how DynamoDB stores data a little below but scaling horizontally is easier with NoSQL databases; in the case of DynamoDB AWS does all the heavy lifting for us3.
Another potential service that AWS offers is called Amazon DynamoDB Accelerator, or DAX for short4. In simple terms, it is a fully managed solution for caching data in-memory. We chose not to use utilize database caching. First, Beekeeper's database queries are already fast. DynamoDB is a NoSQL database similar to a hash table where the value of each key in the hash table is a binary tree. The partition key is the key in the hash table and allows you to spread your data across an unlimited number of nodes (this allows scaling). DynamoDB uses the partition key's value as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored. Our partition key is the user token.
This means that whenever we perform a read of the table looking for a particular token we have a time complexity of O(1) to find that primary key. Then, an O(log n) binary search is made through that item's collection of data which is just three properties. DAX can optimize things further by placing data in-memory. When queries are made for that same data again DAX can provide an in-memory response in O(1) constant time.
Beekeeper does make repeated queries when the frontend JavaScript polls every 20 seconds; that polling triggers a read of the database to see if the token is present in the database table. The benefit of DAX is going from single-digit millisecond latency to microseconds but because Beekeeper waits 20 seconds to make these queries anyway, capturing the efficiency that DAX gives is not critical.
5.4 Validating Users With Cookies or Query String Parameters
Beekeeper's infrastructure relies on being able to track users to determine whether or not to grant them access to the final destination. We came up with two valid options for tracking users each with its own set of pros and cons. In both cases, Beekeeper generates a unique token for each visitor to the waiting room. That token needs to be given to the visitor so that we can track them during their interaction with the virtual waiting room. The two approaches we considered were 1) cookies, or 2) query string parameters plus IP address.
Our current implementation is a cookie-based approach but let's evaluate using query string parameters first. Instead of the Producer Lambda setting a cookie, it could have set query parameters that contained the token like so:
https://beekeeper-sealbrew-s3.s3.us-east-2.amazonaws.com/index.html?token=7ght63
Now the client would be sitting in the waiting room with query parameters tacked onto the URL. When the client-side JS makes an AJAX request to "/polling", those query parameters would need to be sent along, too.
That can be done with client-side JavaScript like this:
const urlParams = new URLSearchParams(window.location.search);
urlParams.toString();
Ignoring the possibility of augmenting this approach with an IP address for the moment, what are the downsides to putting the token in the URL query string? The token is exposed and visible in the URL string. Once someone goes through the waiting room to the final destination they'll know their token is valid and they could share it. A different user could modify their waiting room URL query string and they would be redirected to the final destination on the very first polling cycle. Even further, the sharer doesn't just know a valid query string now, they know the URL of the final destination as well. That user could then share the final destination URL in its entirety (with a query string that contains a valid token). Someone else could then copy/paste that into their browser's search bar and instantly skip the waiting room altogether. Even if the final destination is doing a check by hitting our "/client" endpoint the user will be valid.
Given that using the token in the query string alone is not sufficient, we explored combining it with an IP address. When a new user visits the waiting room link the Producer Lambda, with help from the API Gateway, would record the user's IP address and associate it with a new unique token. The Producer Lambda would then pass the IP address and token to the queue and return the token to the user in the form of a query string. With these two associated pieces of information a user can now make an AJAX request, free of cookies, and if their IP address and query string match an existing database entry, be forwarded to the origin. This IP address query string solution has some flaws. Query strings are lost if a browser is closed, meaning a user would have to revisit the initial link to get a new string and be placed at the end of the line. Secondly, IP addresses are not static and are generally regarded as an unreliable way to track users. This is because IP addresses can be spoofed (i.e. a user fabricates their IP address) and IP addresses can change (this is an issue with mobile users that can change addresses as they travel).
For the aforementioned reasons, we settled on a cookie-based approach. With a cookie, things are hidden from view and if the "/client" check endpoint is used, Seal Brewing can prevent people from skipping the waiting room. Cookies, however, have their own challenges.
5.5 Same-Origin Policy, CORS, and Cookies
Beekeeper has three (3) different origins in our infrastructure.
-
The promotional URL sent to users. Seal Brewing will send this to their users in promotional emails or posted on Twitter, etc. This points to a resource on the API Gateway. This is randomly generated by AWS and might look something like this:
https://p0xoaomdfe.execute-api.us-east-2.amazonaws.com/prod/beekeeper -
The URL where the waiting room exists. This is the URL of a static asset in the S3 bucket. When a user tries to visit #1, they are given a cookie and redirected here. This is randomly generated by AWS and might look something like this:
https://beekeeper-sealbrew-s3.s3.us-east-2.amazonaws.com/index.html?p=0 -
The final destination URL. This is where the promotion lives on Seal Brewing's infrastructure. This might look something like:
https://www.sealbrewing.com/sale
For two URLs to be considered the same origin they must have the same scheme, host, and port. Note that the URLs in #1 and #2 above differ in that they do not have exact matching hosts. The host of #1 is:
p0xoaomdfe.execute-api.us-east-2.amazonaws.com
while the host of #2 is:
beekeeper-sealbrew-s3.s3.us-east-2.amazonaws.com
5.5.1 How Do The Same-Origin Policy and CORS Affect Beekeeper?
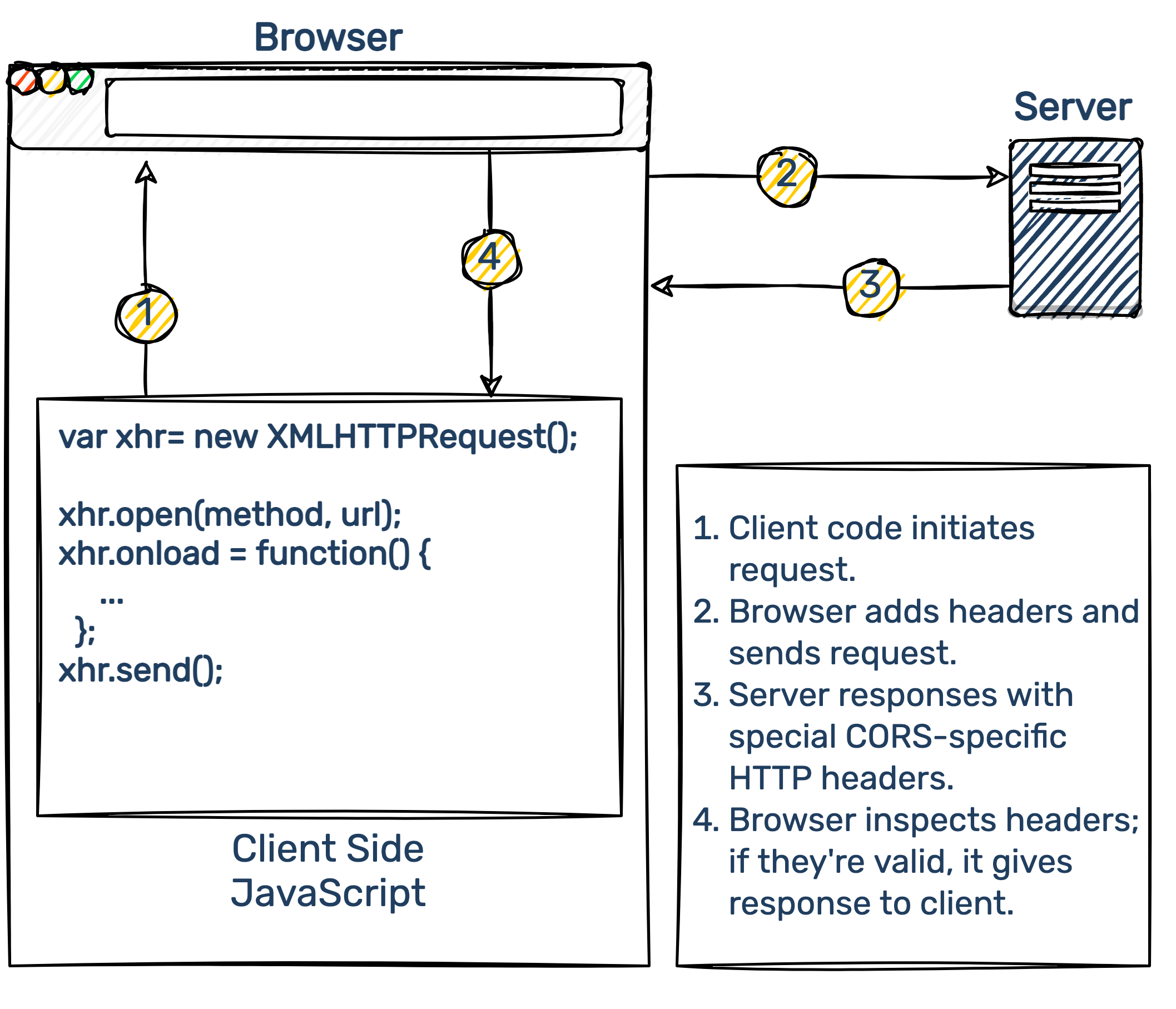
The same-origin policy (SOP) states as a general rule that in-page requests made by client-side JavaScript to origins other than the one from which the request is originating are prohibited.
There are long-standing exceptions to the SOP. For example, an image tag can have an src attribute that points to a different origin. The browser will allow that GET request to go out. Another exception, this time concerning the POST method, is the submission of forms cross-origin. Other notable exceptions exist such as the script tag and the retrieval of CSS cross-origin. Except for these specifically carved-out categories, in-page (i.e. requests made by JavaScript in the page) cross-origin requests violate the same-origin policy and are not allowed by the browser.
Often, there are legitimate reasons for submitting such requests and browsers now accept Cross-Origin Resource Sharing (CORS) as a standardized way around the same-origin policy. CORS allows servers to decide who can make cross-origin requests to it and what those requests can look like. This is done via the HTTP request and response headers. The browser and the server use these headers to communicate how cross-origin requests should be handled. The server uses the response headers to tell the browser which clients can access its API, which HTTP methods and HTTP headers are allowed, and whether cookies are allowed in the request5.
The API Gateway is the origin that set the cookie in the first place. When a user first clicked on the promotional link they went to the API Gateway "/beekeeper" endpoint, which triggered a Lambda and set a cookie, and the API Gateway responded from its origin. That means the client now has a cookie on it corresponding or "belonging" to the API Gateway origin.
The client-side JS needs to be able to send an AJAX request to the API Gateway. This means origin #2 sending an in-page request to origin #1. That's a violation of the same-origin policy and absent specific CORS headers, will fail.
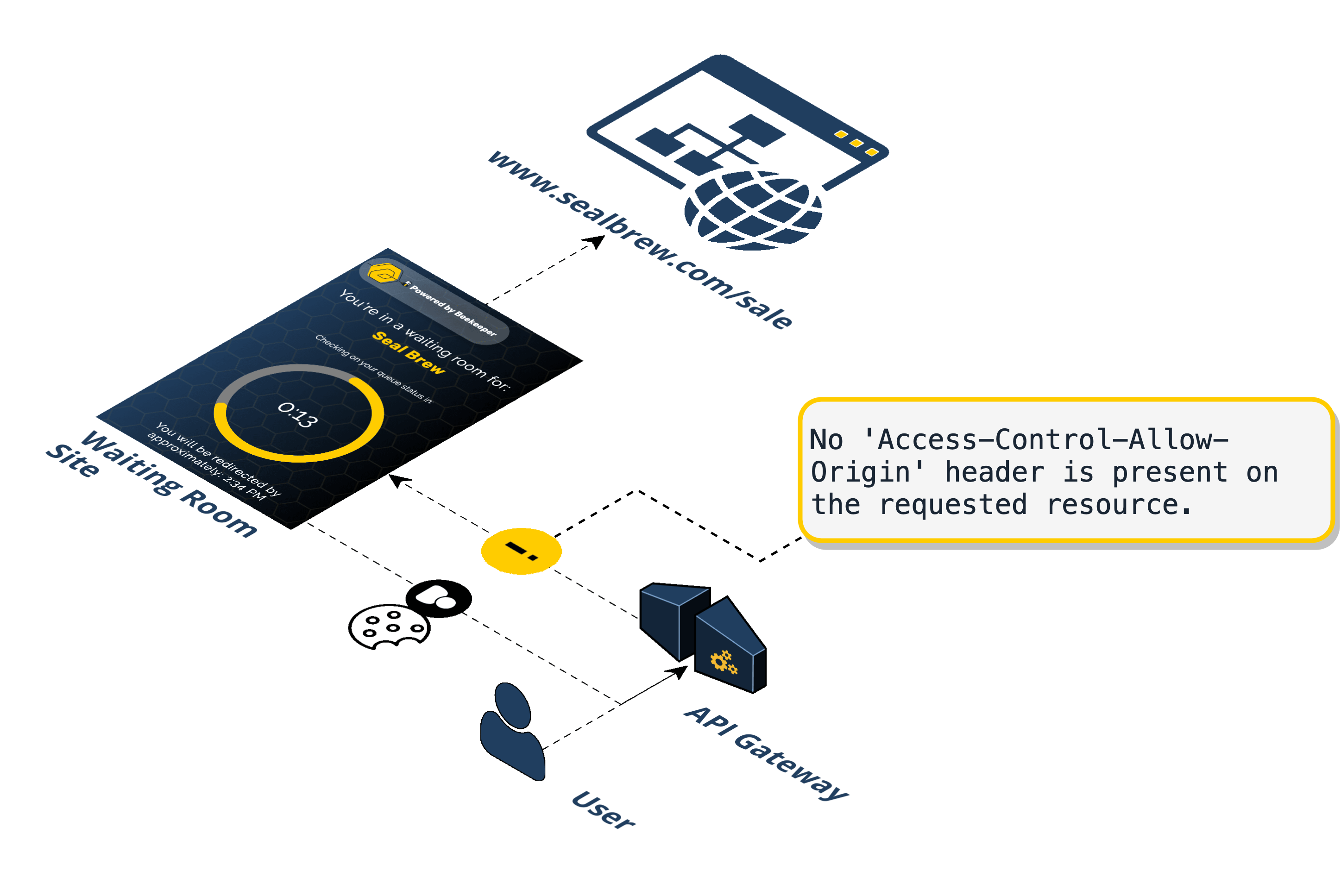
To allow this CORS request, API Gateway can set the following response headers:
'Access-Control-Allow-Credentials': true,
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': '*',
'Access-Control-Allow-Methods': '*'
Wild cards simply indicate that any and all values are acceptable for that property. Notice that we also allowed credentials to be sent.
On the client-side, if we send the AJAX request with vanilla XHR, we would have to make sure to do the following:
const xhr = new XMLHttpRequest();
xhr.withCredentials = true;
By default, the browser does not include cookies on cross-origin requests. You must specifically tell the browser to include any cookies ("credentials") it has stored for the domain this AJAX request is being sent to. But there is a gotcha here. On the server-side, the Access-Control-Allow-Origin header cannot simply be a wildcard as shown above. When sending credentials cross-origin the specific domain must be listed as the value. So we must specify origin #2 there instead of the wildcard shown above.
Cookies themselves have a same-origin policy slightly different from the same-origin policy for HTTP requests. Each cookie has a path and a domain, and only pages from that path and domain can read the cookie. So while the cookie is included in the CORS request, the browser still honors the cookie’s same-origin policy and keeps the cookie hidden from client code. For this reason, something like the document.cookie property cannot read or write the value. Calling document.cookie from the client in the waiting room will return only the client’s cookies, not the cross-origin cookies from the API Gateway6.
Because the cookie belongs to the API Gateway origin and not the S3 bucket origin, we specify two additional properties when setting the cookie. Our code looks like this:
Response.headers['Set-Cookie'] = 'authToken=' + token + '; SameSite=None; Secure;';
The SameSite attribute tells the browser that it is ok to send the cookies in a third-party context and the Secure property tells the browser to only do so when the scheme is secure, i.e. HTTPS rather than HTTP.
As of this writing, Safari presents a further challenge. Cookies for cross-site resources are now blocked by default. Apple is doing this because cookies are used extensively in a third-party context by advertisers for no other purpose except to track users across the Internet7.
For Beekeeper, this means that if a user is using Safari, either on their mobile device or their desktop, the browser will block the cross-origin request with our cookie. For it to succeed, the user must temporarily enable a setting in Safari which Apple calls "cross-site tracking." On our waiting room page, we include a short description of how users can do this. In response to the pressure Apple and Safari have put on this issue, Chrome has also announced its intention to phase out support for third-party cookies by 20228.
Asking users to manually change a setting temporarily in their browser if they are using Safari is not ideal. Safari is a popular browser in a desktop setting and a popular browser in a mobile setting. iOS dominates the mobile market share and mobile market share continues to climb for all use cases, and Safari is the default browser on iOS devices. However, using the alternative query string approach to store the token had significant drawbacks as well. In the end, Beekeeper chose a cookie-based approach because with a future feature discussed below, custom domains with AWS Route53, we can easily generate URLs for the S3 and API Gateway such that they are of the same origin. With a little more work on Seal Brewing's part, the final destination can be of the same origin as well. With the URLs of the same origin, the downsides of the cookie-based approach are effectively mitigated.
Let's move on to a piece of the infrastructure we haven't discussed much yet, the SQS queue.
5.6 FIFO Queues
The Producer Lambda generates a random token, sets a cookie with the token, responds to the client, and puts that token in a queue. We decided that a first-come-first-serve approach would satisfy the largest percentage of typical waiting room use cases. This means we're going to want our queue to operate in a first-in-first-out (FIFO) manner. AWS has two options for us, a standard SQS queue that is "best-effort" FIFO and a strictly FIFO queue. What are the trade-offs?
5.6.1 SQS FIFO Queue
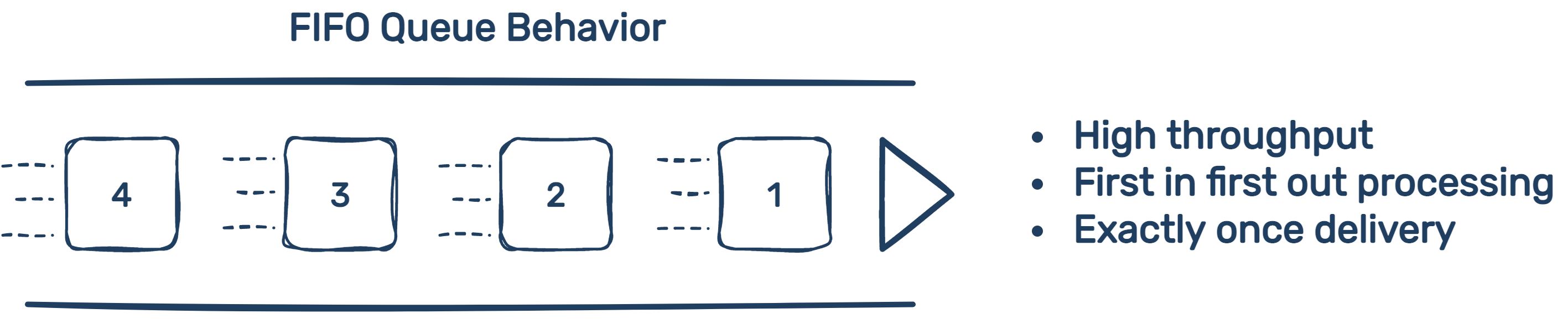
Strictly FIFO queues cannot handle as much throughput as standard SQS queues. FIFO queues can handle 300 API calls per second. Different actions represent different API calls so putting something on the queue might be done with SendMessageBatch while reading from the queue might be done with ReceiveMessage. The restriction of 300 calls per second is per those API methods. That means you can have 300 items in and 300 items out per second. AWS also offers batching which means you can batch multiple items from the queue together in a single call. The batching limit is 10. This means FIFO queues can actually handle 3,000 items in and 3,000 items out per second.
In sum, the benefit of the FIFO queue is exact ordering and exactly-once delivery into the queue. The cost of the FIFO queue is potentially introducing a bottleneck, where suddenly the capability of the queue is drastically lower than the other components.
5.6.2 SQS Queue
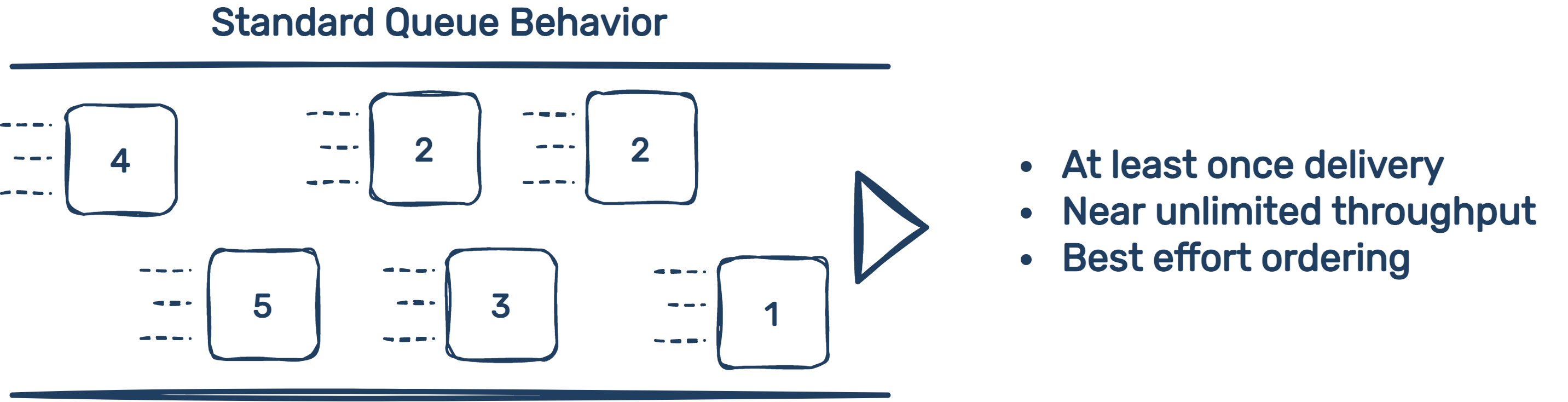
Standard SQS queues have unlimited throughput. But the trade-off is, because of the highly distributed architecture that allows that high throughput, duplicate messages are possible and slightly out of order. Details are scant on what exactly the scope and scale of AWS "best-effort" ordering is and how often duplicates might show up. To analyze the consequences of using a standard queue, suppose we have a user in Sydney, Australia, and a user in Chicago, Illinois. Further suppose the Beekeeper infrastructure was deployed by someone specifying "us-east-2," which is located in Ohio.
Because of network latency, we know that the user in Chicago will have a token that gets put in the queue before the user in Sydney. This example assumes extreme amounts of traffic and AWS is creating some duplicates or outright placing some tokens out of order in the queue. The kind of traffic necessary to cause these issues is not known by us, but we suspect it is quite high. Regardless of the level of traffic, we can get clear about some things: the difference is on the order of milliseconds or even microseconds when talking about AWS "best-effort" creating an occasional duplicate or out-of-order placement. With that context firmly in mind, when we think about the user in Chicago and the user in Sydney we are talking about a separation of latency measured in the 100s of milliseconds. The point is this: who was really "first" from a FIFO standpoint? The microseconds or milliseconds involved with slight non-FIFO behavior by AWS are dwarfed by the magnitude of network latency and its role on how "FIFO-like" the queue is.
What about those occasional duplicates? Beekeeper's writes to DynamoDB are idempotent, meaning no matter how many times you take the same action, the result is the same. There is no harm in trying to write the same token to the database twice.
For the aforementioned reasons we chose to use a standard SQS queue and benefit from the unlimited throughput it provides. After all, the nature of a virtual waiting room is to handle bursty traffic, and absent obvious downside we didn't want to introduce a bottleneck.
5.7 Throttling Traffic Flow
An integral part of our system is sending users from the waiting room to the origin at a specified rate. To achieve this we needed to finely tune the Consumer Lambdas. AWS provides several options for controlling both the number of available lambdas and the frequency they are invoked. Beekeeper tried three different approaches.
Our initial approach utilized a cron job, provided by AWS CloudWatch, to trigger a single Consumer Lambda every minute. Through Simple Queue Services we were able to batch messages in groups of ten and each time a Consumer Lambda was invoked a batch of ten would be polled from the queue, written to the database, and then deleted from the queue (i.e. 1 Consumer Lambda = 10 tokens per minute off the queue). This was accurate, albeit inefficient.
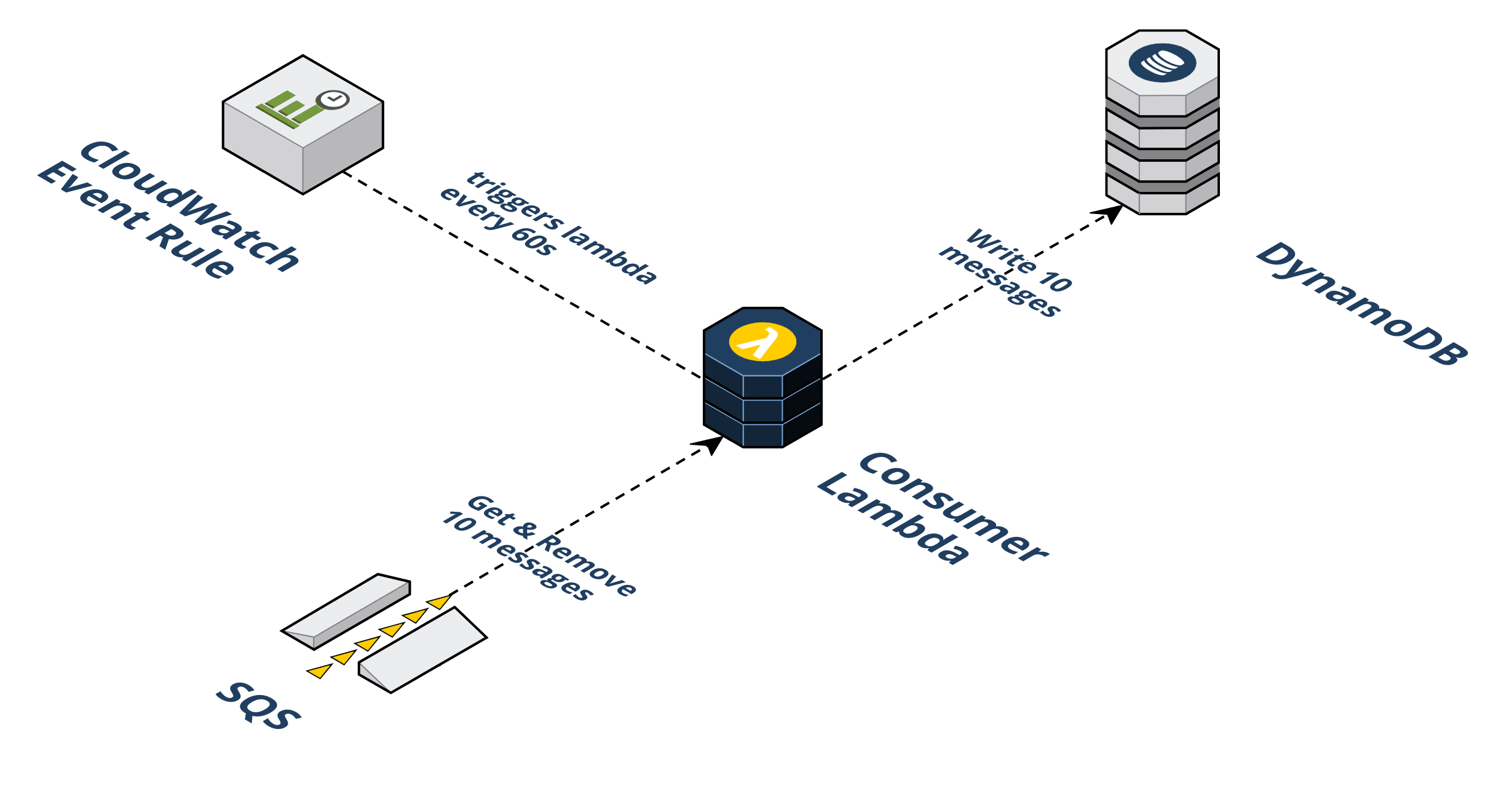
Any increase in the Consumer Lambda rate would also increase the number of lambdas. AWS has a regional concurrency limit of 1000 lambdas. Every Consumer Lambda provisioned reduces the number of available lambdas for the Producer Lambda pool. Reducing our Producer Lambda pool effectively lowers the overall capacity that our waiting room can handle. As an example, if Seal Brewing specified in the CLI that they wanted traffic forwarded to them at 5,000 RPM, 500 Consumer Lambdas (50% of total available) would be needed just for pulling tokens off the queue. This approach does not scale.
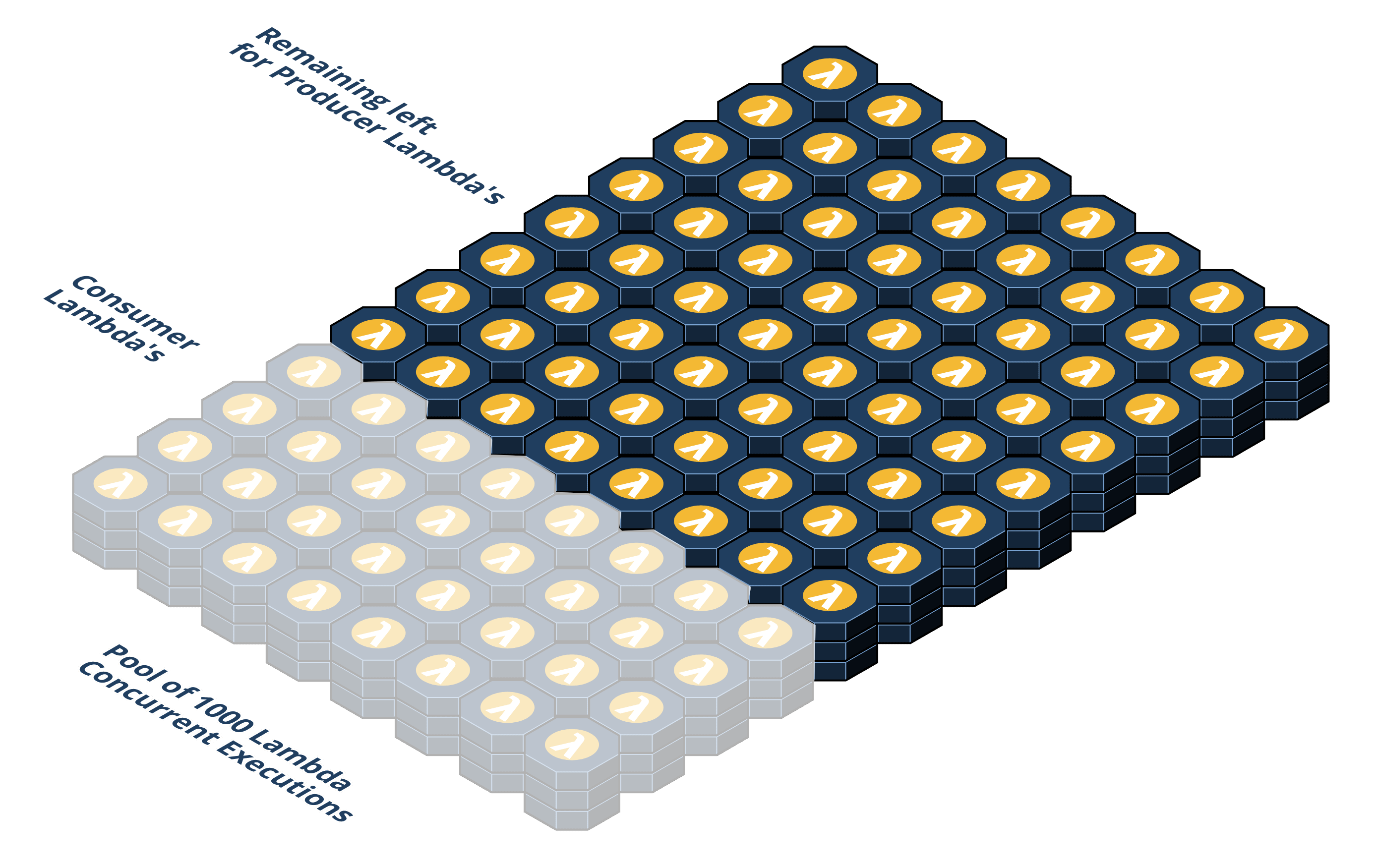
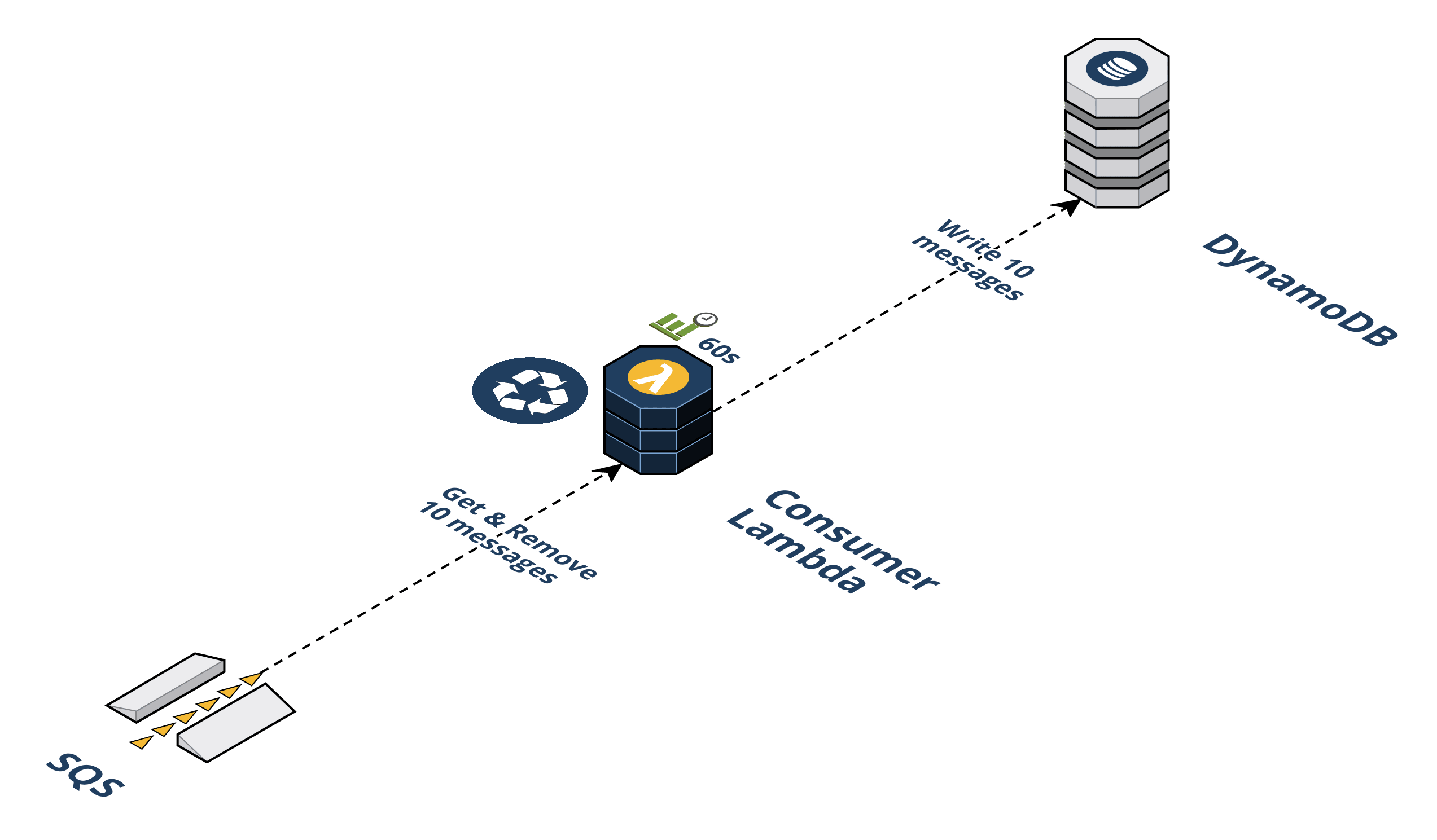
Since we were limited by both the frequency of the cron job (once per minute), and the size of the batch that we can poll from the SQS queue (ten messages), we decided to take a programmatic approach to increase the efficiency of our Consumer Lambda. We implemented a simple loop that runs a number of times determined from the rate Seal Brewing set in the CLI and polls a set number of messages per minute. Instead of scaling the number of Consumer Lambdas, we simply ran the same logic but now for several loops. We were already allotting ample time for our lambdas to execute so extending our loop only helped occupy otherwise wasted time. This approach was accurate as long as the number of loops needed could be completed in time before the Consumer Lambda timed out. Our Consumer Lambdas have 60 seconds to complete their work. From our testing a Consumer Lambda could complete about 150-180 loops, i.e. about 1,500 to 1,800 tokens could be pulled off the queue per minute. The problem was if Seal Brewing selected a rate higher than one Consumer Lambda could handle in 60 seconds, perhaps 3,000 a minute, unexpected behavior would occur. The first Consumer Lambda would try to complete 300 loops, time out, and then re-trigger itself. Because we also configured the Reserve Concurrency for the Consumer Lambdas based on the CLI rate set, another Consumer Lambda would spin up and also try to complete 300 loops. The result was highly inaccurate data above anything more than one Consumer Lambda could handle. This approach scaled but was inaccurate under load.
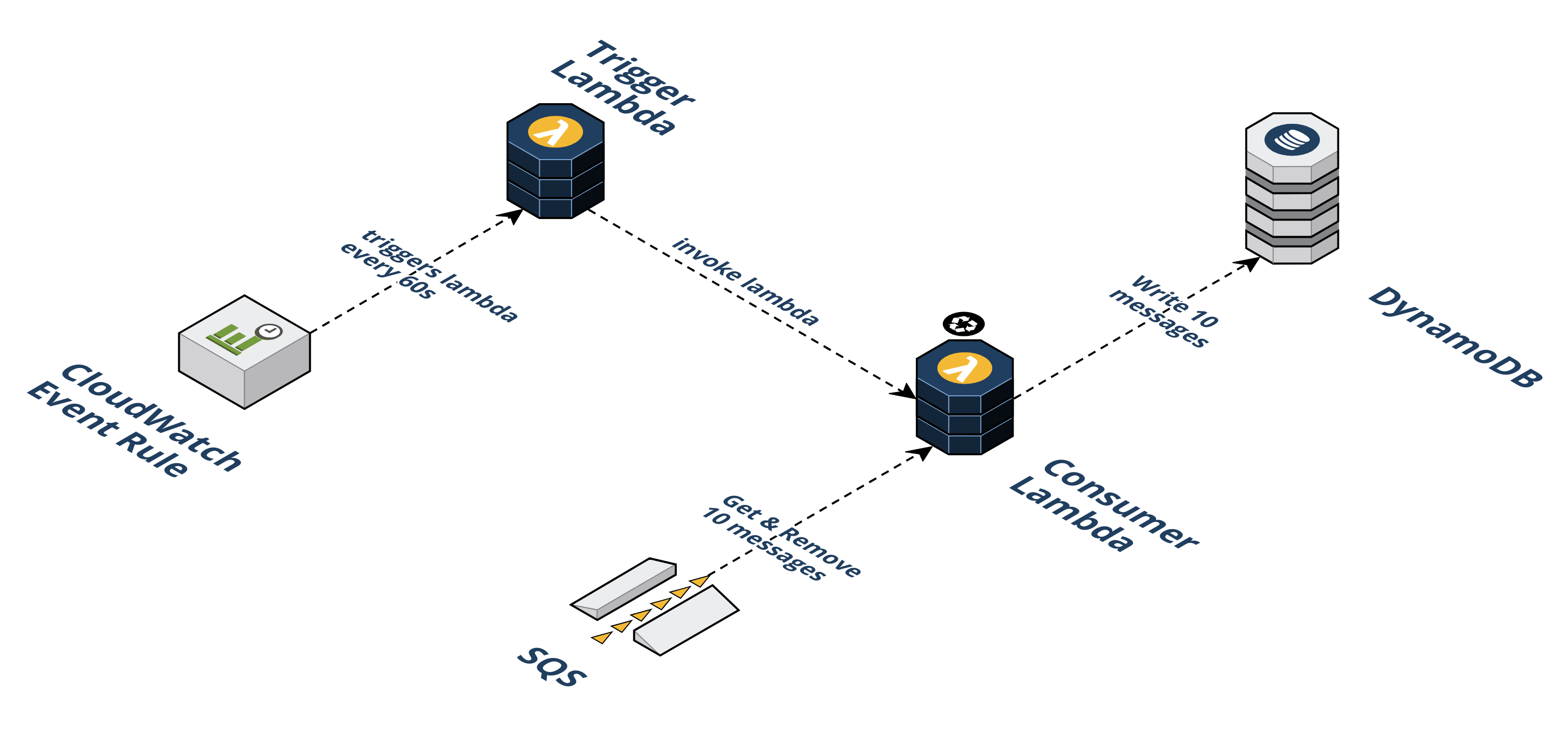
Our third and final approach was cleaner. We introduced a new Trigger Lambda which orchestrates how many Consumer Lambdas to invoke and each Consumer Lambda loops a maximum of 100 times. For example, if Seal Brewing selects a rate of 3,300 RPM, the Trigger Lambda will invoke three Consumer Lambdas and pass an argument to each instructing them to complete 100 loops, and a fourth Consumer Lambda with an argument instructing it to do the remaining 30 loops. The Consumer Lambdas can easily finish 100 loops in 60 seconds (usually about 30 seconds). This final approach solves the problems of the first two: it is both 1) scalable, and 2) highly accurate.
Beekeeper also allows Seal Brewing to optionally change the rate at which traffic is forwarded on the fly. We use an environmental variable on the Trigger Lambda to hold the rate and this variable can be modified.
5.8 Dynamic Rate Throttling
Beekeeper offers an optional feature in the CLI called Dynamic Rate Throttling. This is a feature that protects Seal Brewing from accidentally choosing a rate that their endpoint cannot handle. At a high level, Beekeeper periodically pings the Seal Brewing endpoint and if the average response time degrades to something worse than three (3) standard deviations from an initial baseline check, we slow the rate down.
Beekeeper achieves this functionality by utilizing an extra Lambda we call the dynamic rate throttling (DRT) lambda. This extra lambda would tune the rate of our Consumer Lambda based on the latency of the client's endpoint. We modeled our DRT lambda off of a governor model introduced in Release It! by Michael T. Nygard9.
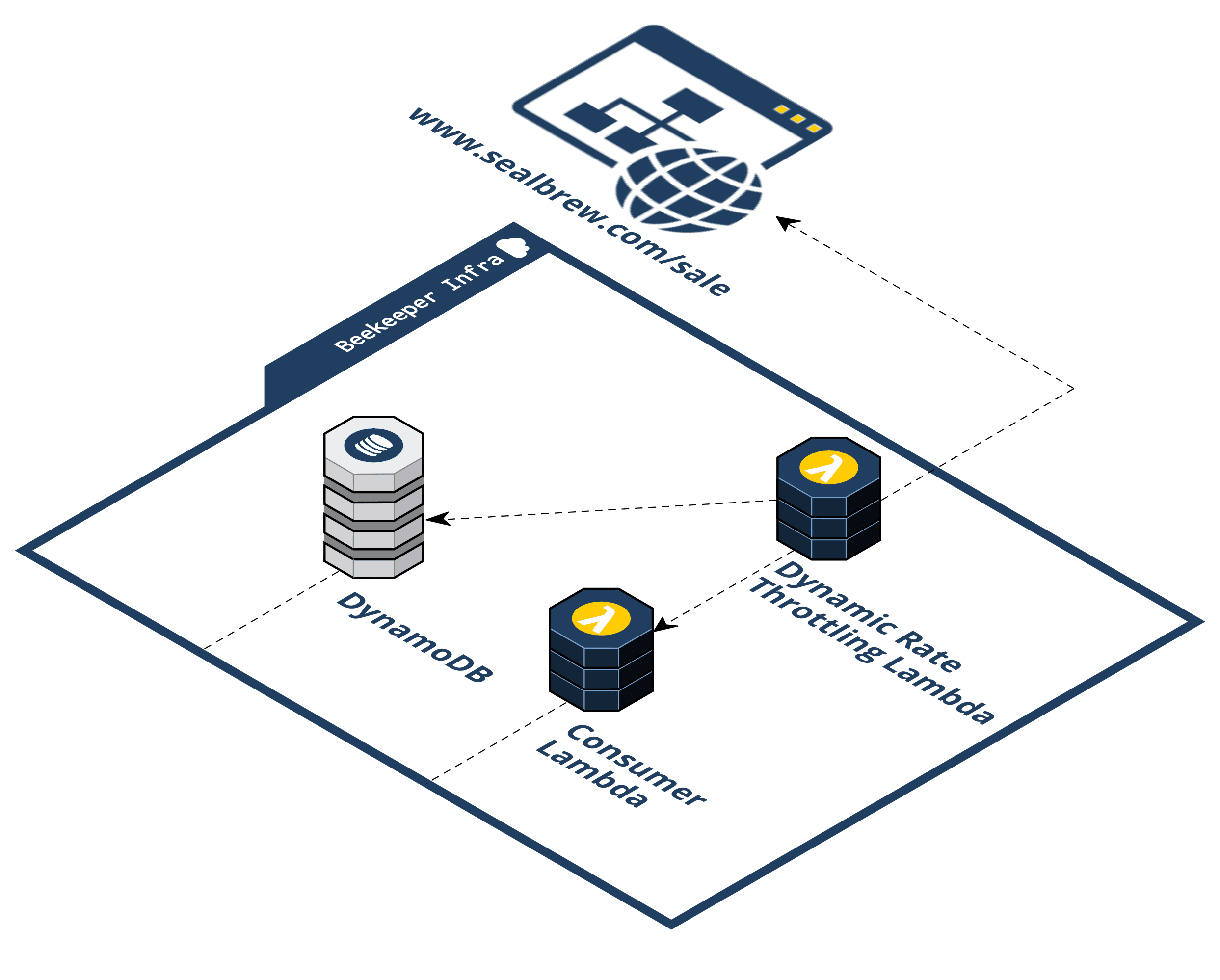
Going back to our example: Seal Brewing has set up their wait room and specified a rate. Everything is going great for the first couple of minutes but customers are taking longer than expected to checkout and now the number of concurrent users on their site is increasing and throwing the health of their servers in jeopardy.
In the above case, the Consumer Lambda has no judgment. It will continue to send users to the site and by the time things go wrong, it might be too late for human intervention. This is where the governor design pattern presented by Release It! comes in. A programmatic governor limits the speed of a system much like the governor in a fancy sports car will prevent a driver from damaging an engine or exceeding some legal limit. Choosing a lambda to run our DRT logic posed an issue. A governor must be stateful and time-aware. A lambda is neither. To give our DRT lambda statefulness we record its actions in our DynamoDB. Before the DRT lambda takes action it first reads from the database. The DRT lambda compares the current latency of the client endpoint to the baseline latency. If the client endpoint is failing this test the DRT lambda throttles the Consumer Lambda rate. Alternatively, if there is a history of rate throttling and the health of the system is passing, the DRT lambda will slowly increase the rate of the Consumer Lambda back toward the starting rate.
Changing the rate too far or too fast in one direction is bad. We want to avoid changing the rate to zero or increasing the rate back to an unsafe level. Our DRT lambda has built-in logic that decreases the amount it can change as it moves farther in one direction. The lambda also takes a slower approach to increasing the rate after a throttle than it does performing a throttle.
The graph below shows how the DRT Lambda would change the rate of the Consumer Lambda (CL rate) as the latency of the endpoint surpasses a statistically derived threshold. The baseline is set by averaging the endpoint latency over a sample set of 20 requests. The upper threshold is set as three times the standard deviation of this sample set. The endpoint latency is calculated by taking another sample of twenty requests and finding their mean. In this way, we ensure that the rate won't be throttled by a few random high latency requests. When a test of the endpoint latency crosses the upper threshold the CL rate is reduced by 50%. When the endpoint latency again crosses below the upper threshold the CL rate is gradually increased at a rate of 25% of the difference from the original CL Rate and current CL rate.
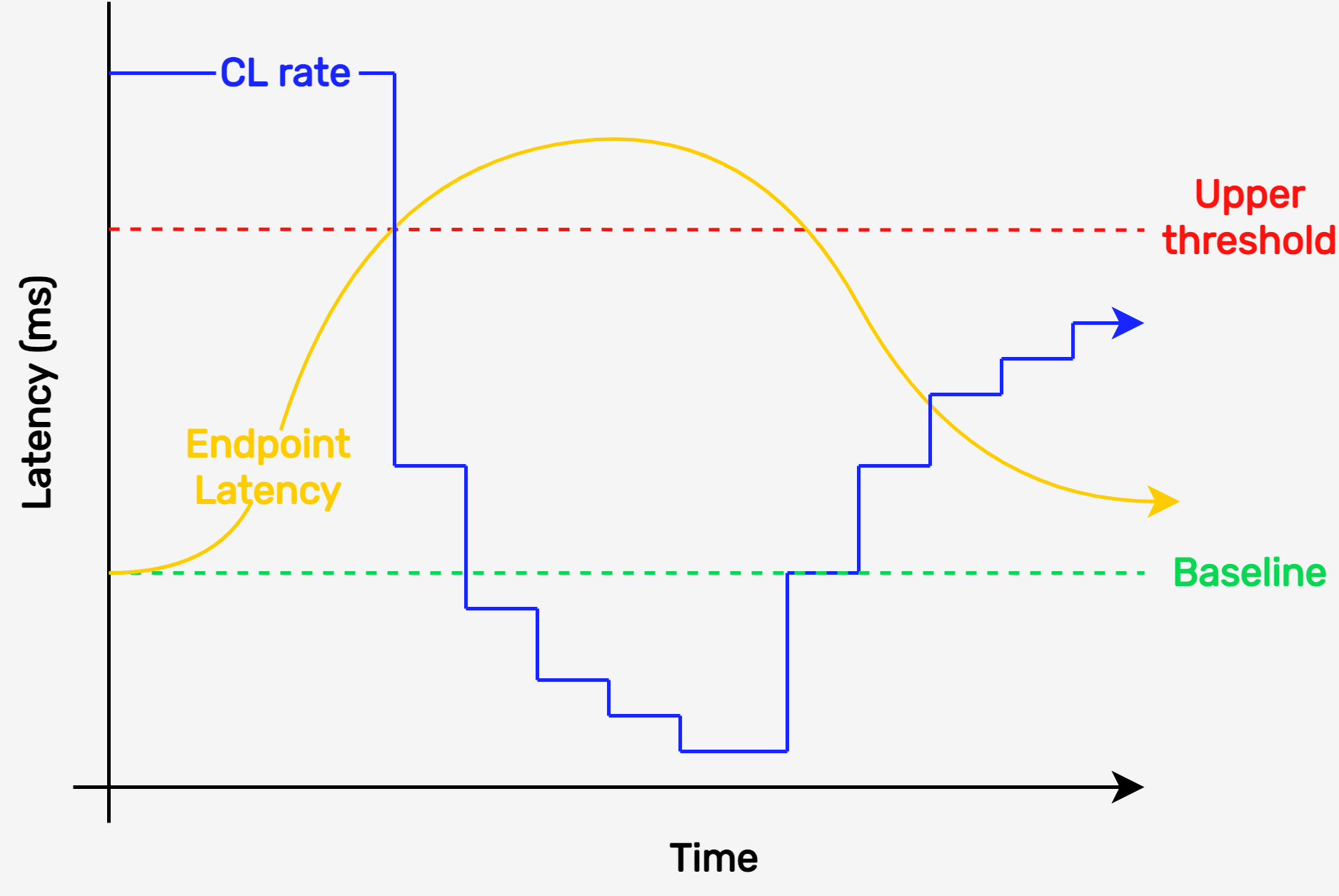
5.9 Load Testing
Load testing a deployed waiting room infrastructure posed a unique set of challenges. Our project relies heavily on the capacity and elasticity of AWS. To fully test our deployment we would need to load test at levels approaching the capacity of AWS components. This is not an easy feat seeing as those limits could approach 10,000 queries per second. Using an open-source load testing package (artillery.io) and four different computers we were able to simulate around 140 requests per second.
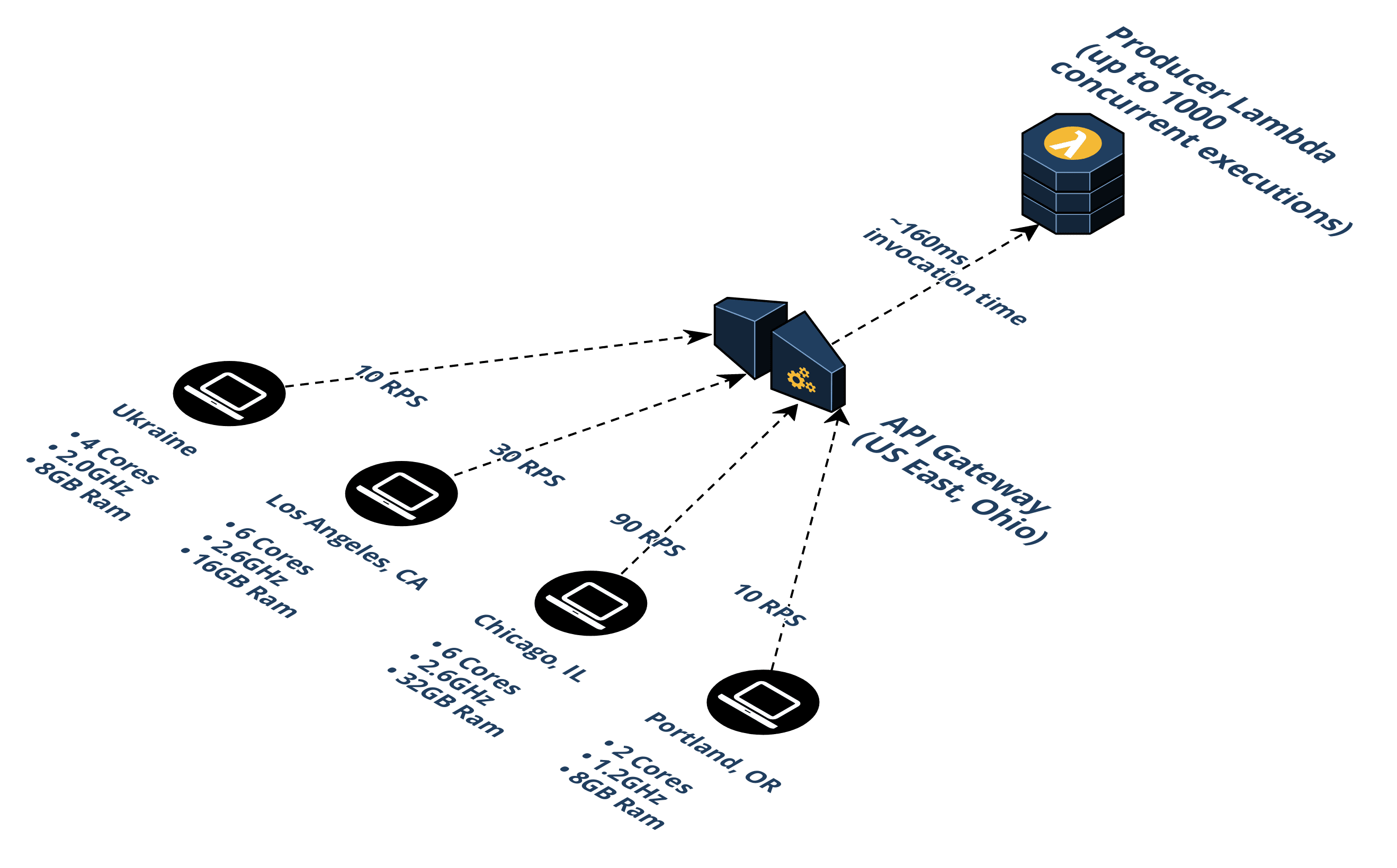
From this amount, we were able to extrapolate. Most of AWS's services have inherent upper limits at some point. For example, the API Gateway has a limit of 10,000 RPS and the S3 bucket has a maximum of 5,500 GET RPS. Similarly, the SQS has a near unlimited throughput. There is no reason to test those. Lambdas, however, are limited to 1,000 per region. Our specific area of inquiry was to figure out what level of traffic would max out the Lambdas.
The results of our load test over a period of 8 minutes show that the Producer Lambda has an average total duration time of roughly 160 milliseconds. This duration time consists of both the cold start time and the lambda invocation time. A lambda cold start happens when AWS needs to provision a container so that it can execute a lambda function and this happens on the first request that comes in after deployment or in the case when all the other containers are being used and there are no other available ones.
Once we identified the Producer Lambda's average total duration time of 160ms, we were able to estimate that the number of times the lambda can execute per second is around 6.25 (1,000 / 160). This means that if the maximum number of concurrent lambdas allowed is 1000, then the maximum requests per second Beekeeper can handle before it uses up all the available lambdas is 6,250 RPS (*theoretical limit: assuming no Consumer Lambdas).
5.10 Bottlenecks
It's worth remembering that the point of all this load testing and bottleneck discussion is to figure out how much traffic Beekeeper can handle. Without that, we do not know what Beekeeper's target use case is. Below is a diagram of some of the AWS limitations of the infrastructure pieces that Beekeeper uses. At a glance, you can tell that the DynamoDB, API Gateway, and SQS have a much higher capacity compared to the S3 bucket and Lambda. These are not potential bottlenecks.
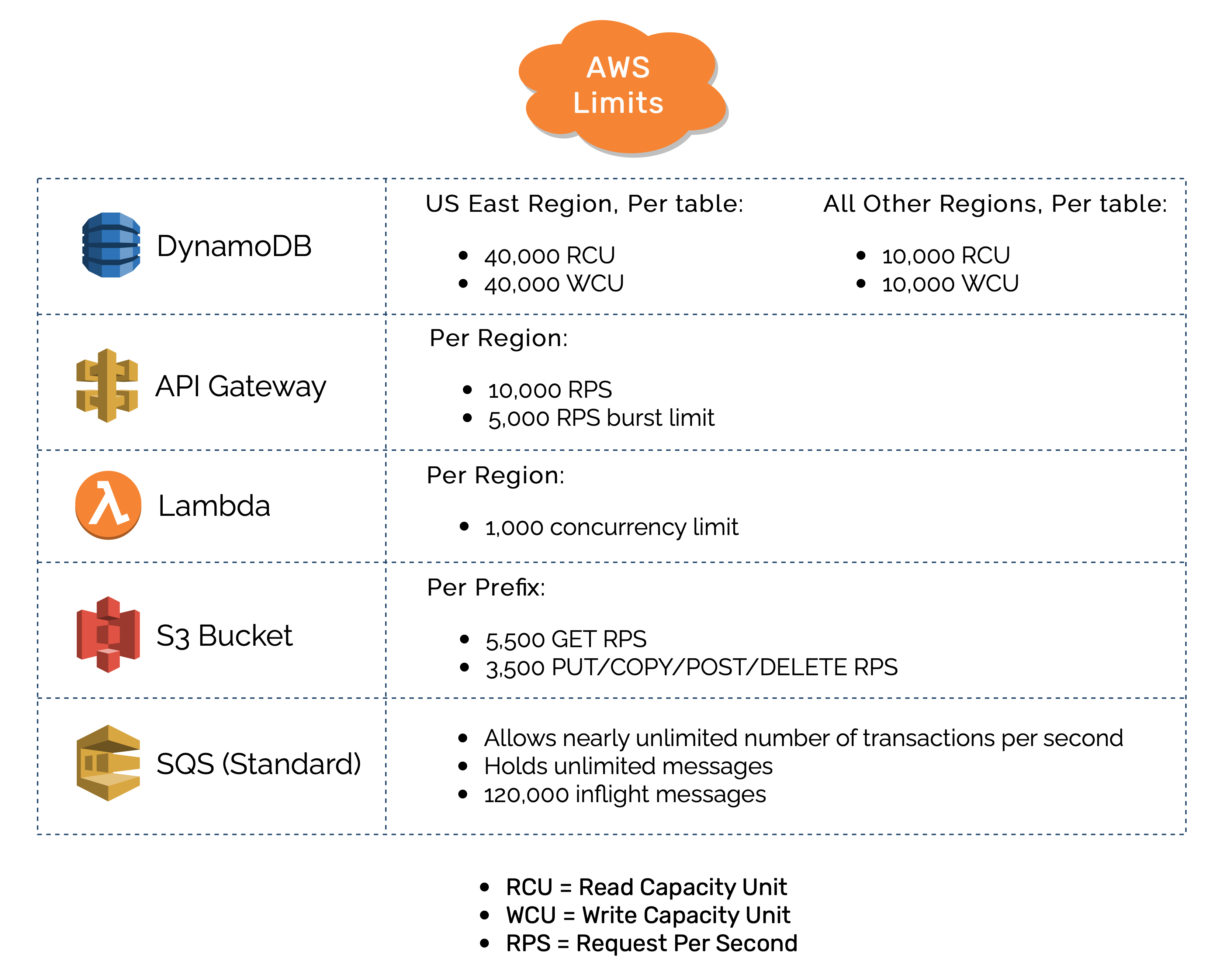
A bottleneck occurs when the capacity of a system is limited by a single component. As discussed above, Beekeeper maxes out the 1,000 Lambda limit around an estimated 6,250 RPS. And as can be seen in the chart, the S3 bucket can handle 5,500 GET RPS per prefix. Therefore, our bottleneck is the S3 bucket and potentially the lambdas because that is only an estimate. If the number of visitors to the API Gateway exceeds 6,250 RPS, then both the Producer Lambda and S3 bucket will be throttled.

5.11 How Much Traffic Can Beekeeper Handle?
As with any infrastructure, Beekeeper has constraints and those are imposed both by built-in limits from specific AWS services and Beekeeper’s design pattern. Finding the answer to our traffic capacity defines our current use case, and it can provide insight into how Beekeeper could be scaled further. Therefore, it is an important question, but it is involved and highly fact-specific because there are several variables in play. There are three primary numbers to think about when discussing Beekeeper's traffic "capacity": 1. incoming traffic rate to the waiting room, 2. outgoing traffic rate from the waiting room to the final destination, and 3. standing room capacity in the waiting room.
Beekeeper is constrained by the requests its individual components can handle. Recall that lambdas are responsible for both #1 and #2 above; scaling up to handle incoming traffic and taking tokens of the queue. Standing rooom capacity is dependent upon the capacity of the API Gateway as explained below.
5.11.1 Incoming Traffic Capacity
Beekeeper can handle about 5,500 RPS coming in. This is the S3 Bucket hardware limit, which has the lowest throughput limit of any of our AWS services. Close behind that is the 6,250 RPS limit imposed by the lambdas and discussed above.
5.11.2 Outgoing Traffic Capacity
As mentioned, this is dependent on the lambdas. We need Producer Lambdas for incoming traffic and Consumer Lambdas for pulling off the queue. We only have 1,000 lambdas to work with per AWS region. This question asks, how fast can Seal Brewing specify, as a rate in the CLI, that they would like traffic forwarded? It depends, and it involves math and assumptions about the scenario. The theoretical maximum Seal Brewing could set for the rate would be about 270,000 RPM.
That number can be derived as follows. We start with the understanding that for 270,000 RPM outgoing to be possible the system needs to handle at least that fast of a rate on the way in. Given 270,000 RPM outgoing, would we have enough Producer Lambdas left to handle that rate incoming?

Conclusion: This works and we have enough lambdas. The maximum rate that Seal Brewing could select in the CLI, under any scenario, is about 270,000 RPM, i.e. 4,500 RPS. It's extremely unlikely that anyone would want traffic forwarded this fast.
5.11.3 Standing Room Capacity
We've established that a lot of traffic can flow into the waiting room and a lot of traffic can flow out from it. Consider a case in which incoming traffic to the waiting room far outpaces outgoing traffic to the endpoint. A large number of concurrent users will accumulate in the waiting room. Each concurrent user in the waiting room must send a request to the API Gateway to check on their status. A hypothetical case where the waiting room has 200,000 concurrent users will overwhelm the API Gateway’s stated capacity.

We chose every 20-second polling because 200,000 queued waiting room visitors is an appropriate target use case, and more frequent polling is a better user experience for the queued customers. In conclusion, while not suitable for the largest of events, Beekeeper is certainly not limited to just small events, either. It is a robust open-sourced solution that does what it set out to do.
5.12 Scaling Beyond Beekeeper's Current Design
5.12.1 Scaling a Single Beekeeper Deployment
Now that we've established the current use case, how might we approach scaling Beekeeper for even larger events? The first step might be to squeeze more capacity from a current infrastructure deployment.
S3 Bucket (incoming traffic rate). The S3 bucket has a hardware limitation of 5,500 GET RPS. It would be feasible to create multiple buckets with identical static assets and distribute incoming traffic from the API Gateway amongst them. In other words, horizontally scale the S3 bucket.
Lambdas (both incoming and outgoing traffic rate). The default concurrency limit is 1,000 lambdas per AWS region. As discussed, this equates to a 6,250 RPS limit on incoming traffic and also affects the outgoing traffic rate. This 1,000 concurrency limit is a soft limit and can be increased, for free, by contacting Amazon. How much this can be increased by is not known, but ancedotal reports mention five-fold increases for free. This is again an example of more horizontal scaling. It's also worth noting that our current Consumer Lambda code only utilizes approximately 50% of the time we allocate to them; it only takes about 32 seconds for each of them to complete their 100 loops. We could squeeze more loops out of them and complete more work.
API Gateway (standing room capacity). In the case of the API Gateway, we could poll it less often, perhaps every minute instead of every 20 seconds. That's a single line of code to increase the standing room capacity from 200,000 to 600,000. We could also look into implementing WebSockets to prevent wasteful HTTP request/response cycles, but of course that would simply move the bottleneck to other hardware required to maintain all those open connections.
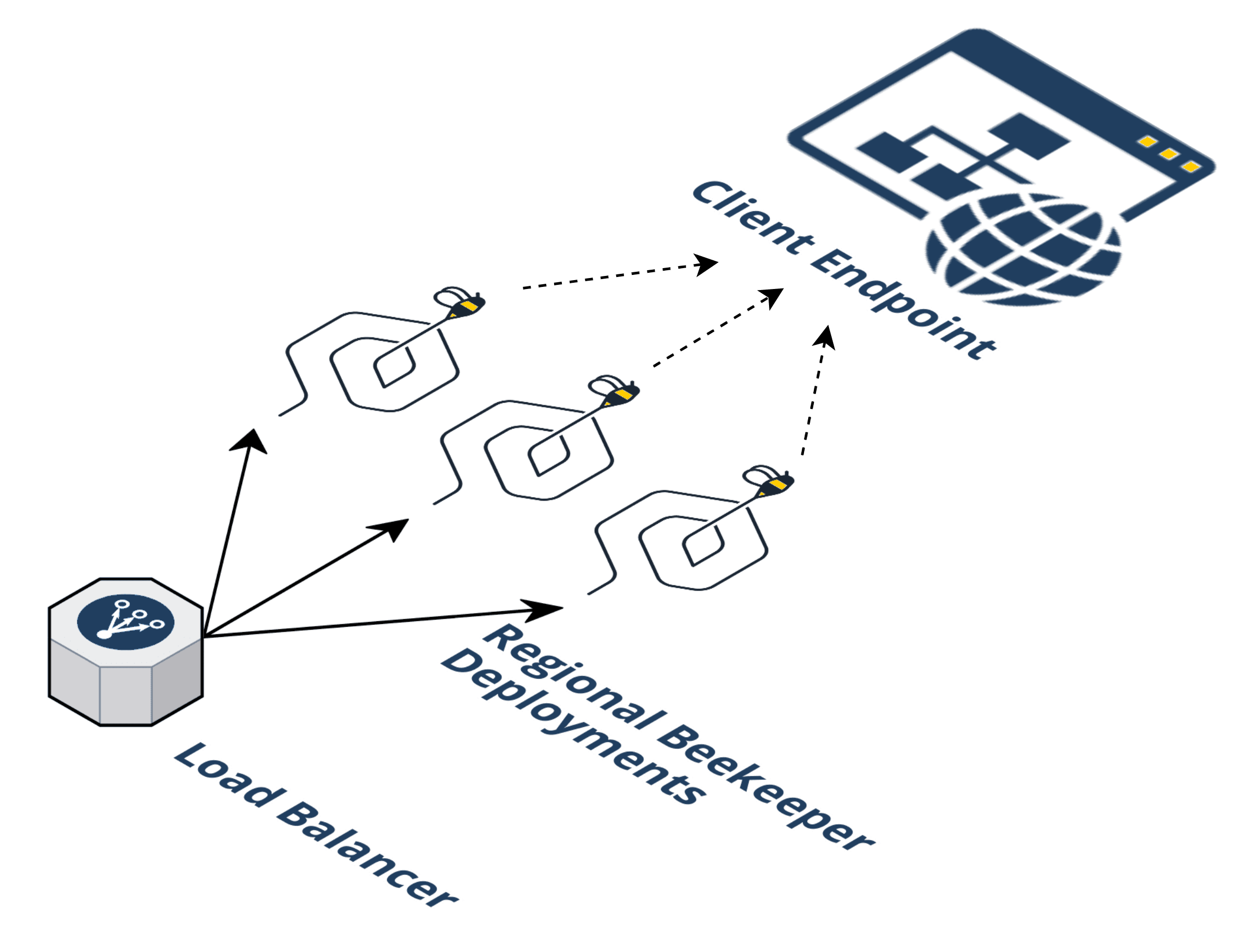
5.12.2 An Elegant Solution: Multiple Regional Beekeeper Deployments
Now we are faced with an important design decision. At some point, do we continue patching our infrastructure as new bottlenecks arise or is there a more elegant approach? One existing solution might be to use an Elastic Load Balancer in front of separate regional wait room deployments, i.e. an entire Beekeeper infrastructure in "us-east-1" and another in "us-east-2", etc. In this way, the traffic from an event capable of overloading a single Beekeeper deployment is distributed, reducing the burden of a single waiting room. Scaling our design pattern horizontally is all that is required to jump from our current use case to larger, globally distributed events.
6. Future Features
6.1 Branded Waiting Room Experience
One of Beekeeper's current features is a CLI option whereby the user specifies what name they'd like to appear on the waiting room page. This is to avoid confusion and let the waiting room visitor know they're in the right place. A good next step would be to allow Seal Brewing to upload their logo and perhaps upload their own HTML and CSS for a completely branded waiting room experience.
Taking things even further, we could set up the ability through Amazon Route53 to create custom domains for both the promotional URL link and the waiting room page link. These could be separate endpoints on the Seal Brewing origin. Doing so would eliminate the complications of CORS requests discussed previously. However, it would be a much more difficult implementation for Seal Brewing and we would have to take care to craft a user guide to walk through configuration and the necessary DNS changes on their end.
6.2 Bot Protection
Our waiting room is accessed via a link. This link could be accessed by some malicious actor that decided to flood the URL with GET requests putting a lot of tokens in the queue and creating an unusually long waiting room experience for genuine visitors. AWS has a service called Web Application Firewall, or WAF, that can set rules such as IP throttling and could be added to Beekeeper’s architecture to prevent this type of malicious action.
6.3 WebSockets: Push Versus Pull
Beekeeper implements a polling approach from the waiting room to check whether a given site visitor is allowed to redirect to the final destination. Instead of polling for the status of their token, we could implement WebSockets and push this information. We would maintain an open connection to the waiting room after initially establishing it and when a token is written to DynamoDB an event would fire triggering a Lambda that could push that information to the waiting room. Polling involves some wasteful HTTP request/response cycles, especially when we might already know based on the number of people in line and the rate at which they're leaving the queue that it could be quite some time until this particular client is up in the queue.
7. References
[2] https://wondernetwork.com/pings/Los%20Angeles
[3] https://www.alexdebrie.com/posts/dynamodb-no-bad-queries/
[4] https://aws.amazon.com/dynamodb/dax/
[5] https://livebook.manning.com/book/cors-in-action/chapter-1/13
[6] https://livebook.manning.com/book/cors-in-action/chapter-5/77
[7] https://webkit.org/blog/10218/full-third-party-cookie-blocking-and-more/
[8] https://blog.chromium.org/2020/01/building-more-private-web-path-towards.html
[9] https://pragprog.com/titles/mnee2/release-it-second-edition/
Presentation
Our Team



